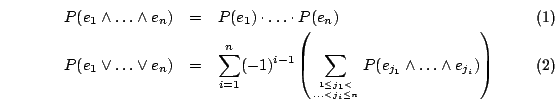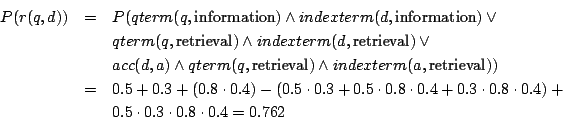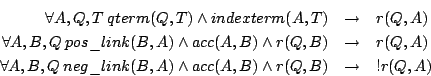|
|
|
TCDL Bulletin What did the Others Say?Probabilistic Indexing and Retrieval Models in Annotation-based DiscussionsIngo Frommholz AbstractAnnotations, supporting different facets of Digital Libraries, can manifest themselves in different forms and dimensions. In the form of shared, textual and nested annotations they can be used to model discussions. Such discussions contain additional information that can be interesting for both document and discussion search. In my thesis I am going to develop a formal annotation model and, based on this, discuss and evaluate probabilistic indexing and retrieval models for annotation-based document and discussion search. 1. MotivationThere is a lot of ongoing research in the design and development of software systems incorporating annotations. As a recent study shows [3], annotations support different facets of Digital Libraries (like creation, management, access and retrieval, and effective use) in several ways. Annotations can manifest themselves in different forms and dimensions, ranging from simple text highlighting and personal notes through (typed) links between documents up to nested and shared annotations with which collaborative discussions about a specific topic are realised. In the latter case, annotations and the annotated object form an annotation thread. Such threads consist of (one or more) documents and nested annotations discussing the documents and their content. Depending on one's viewpoint, either a document and its annotations are equal or annotations are seen as auxiliary documents for the document they are annotating. An example of annotation threads are the talkback discussions found in ZDNet News (http://news.zdnet.com/), and also the annotation model created within the COLLATE project, where threads are formed with annotations and discourse structure relations among them [5]. When regarding documents and annotations as equal, annotation threads are similar to discussion threads as we know them from USENET News or email discussion lists. In fact, articles in discussion forums are annotations. The nodes in the annotation thread and the links among them form a certain kind of document context for each node, the context of "what others said about a document or its content". While in traditional information retrieval, lots of models and methods have been developed for document search, the idea of using the annotation context for retrieval is quite new. In my thesis, I will define and evaluate methods to employ the annotation context for information retrieval. There are two main scenarios which can be identified:
In both scenarios, it is crucial to consider the context spawned by the annotation thread, which in collaborative discussions means taking into account what others said about a document. 2. Proposed ResearchWhen showing how to exploit the annotation context for information retrieval, three main tasks have to be done:
In my work I will focus on the creation and application of probabilistic retrieval models, either logic-based or statistic. Before discussing retrieval issues, I propose a formalisation of annotations and annotatable objects1. 2.1 Annotatable Objects, Annotations and Annotation ThreadsLet DO be the set of digital objects in our knowledge space. An annotatable object is an object that can be annotated. Let AO be the set of annotatable objects; AO is a subset of DO. Examples of such annotatable objects, which are application-dependent, might be whole documents, document passages, sets of documents, folders, persons, locations, and other annotations. Annotatable objects might be parts of other objects. To express this, we define a special containment relation among objects: Let o,o' be digital objects. We say that o contains o', if o' is a part of o and o' ! = o. For instance, in a document a section s might be a part of chapter c. A textual passage p is contained in the corresponding document d. A selection of an image is part of its image. The set of annotations A is a subset of DO. An annotation a is a tuple <AOa,Ta,Ma,ba> with AOa subset of AO as the set of annotatable objects the annotation refers to; due to the view of annotations as metadata [3], AOa must not be empty. Ta is the set of annotation types of a. Ma is the set of attribute-value-pairs containing metadata about the annotation. ba is the body of the annotation, which might consist of text, references, and graphics. The definition of an annotation is flexible, covering certain annotation scenarios as the following examples show.
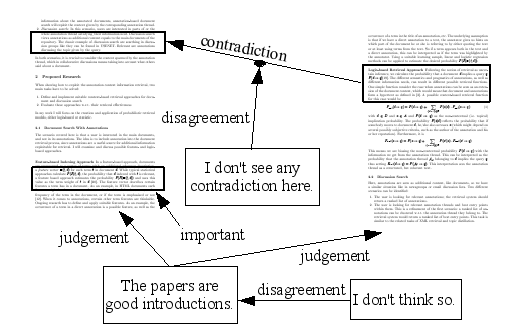
Example 1: Textual Annotations. Imagine the system lets users write (textual) comments on one or more documents. Let d1 and d2 be documents. The user Joe judges that these are good introductions to a certain topic, and expresses this judgement by writing a new text b="The papers are good introductions", so we get a= <{d1,d2},{judgement},{(author,"joe")},b> Going on with the example, another user, Sally, disagrees with Joe's view and expresses this by annotating the body of the first annotation: a'= <{b},{disagreement},{(author,"sally")},b'> with, e.g., b'="I don't think so" as the textual sign of this annotation. Note that a' actually annotates b. If a' was referring to a instead of b, this could be interpreted as if Sally disagrees that a is a judgement! Example 2: Referential Annotations. Assume two documents d1 and d2. Joe finds a statement in a passage that contradicts another statement in another passage, so he identifies the two passages p1 part of d1, and p2 part of d2, and connects them with a reference in the annotation body: a= <{p1},{contradiction},{(author,"joe")},"p2*"> with p2* meaning "reference to p2". Sally again disagrees with Joe's views and creates another annotation: a'= <{a},{disagreement},{(author,"sally")},b'> with b' something like "I don't see any contradiction here." The first annotation creates a typed link between passages. The second one annotates this link, but not the passage p2, so a' refers to a. Example 3: Highlight Annotations. In a document d, Joe finds a passage p very interesting and highlights it. a= <{p},{important},{(author,"joe")},"_"> ("_" means that the tuple item is empty). The annotation examples are depicted in Fig. 1. In my research I focus on nested, textual annotations. Nested annotations can support collaboration and can be the building blocks for discussion. Nested annotations together with the documents to which they refer form an annotation thread. Annotation Thread. An annotation thread is a directed, acyclic graph G=(N,E) with N as the set of nodes and E as the set of edges between nodes. A node n represents either an annotation or a document, or parts of them; leaves in annotation threads are always documents. (n',n) is an edge if n is an annotation of n' or n' is part of n. The function l labels edges with a set of link types; let l((n',n)) = Tn' if n is element of AOn' or l((p,n))={"part_of"} if p is part of n. 2.2 Document Search with AnnotationsHere we regard a scenario where a user is interested in the main documents, and not in its annotations. Retrieval functions return a ranking of documents based on their corresponding retrieval weight w.r.t. the query. 2.2.1 Retrieval OptionsSeveral options w.r.t. document search can be identified when incorporating annotations. In principle, these are relevant for discussion search as well.
Access to documents through annotations
Vocabulary problem
Topic emphasis
Highlighting 2.2.2 Feature-based Indexing ApproachIn a feature-based approach, a document is represented as a vector of terms with an additional relevance description, a feature vector x(t,d) for each term t in document d. While typical statistical approaches calculate P(R|t,d), the probability that d indexed with t is relevant, a feature-based approach estimates the probability P(R|x(t,d)) and uses this value as the term weight of t in d [10]. The feature vector describes certain features a term has in a document. As an example, in HTML documents, such features might be the occurrence of a term in the title of the document, or the frequency of the term in the document, or whether the term is emphasised or not [13]. When it comes to annotations, certain other term features are possible. Ongoing research has to define and apply suitable features. As an example, the occurrence of a term in the body of a direct annotation a of a document d is a possible feature. 2.2.3 Logic-based Retrieval ApproachHere we follow the notion of retrieval as uncertain inference [19]. The different semantics and pragmatics of annotations, as well as different information needs, can result in different possible retrieval functions. One simple function considers the case that annotations are seen as an extension of the document content. We say that a document is relevant to a query if at least one of its index terms is also a query term, or if there exists at least one annotation that is accessed and relevant to the query. A possible formulation of the problem in predicate logic would be
where qterm(q,t) states that t is a query term of q, indexterm(d,t) means that d is indexed with term t, acc(d,a) says that when accessing d, we also access a, and finally r(q,d) expresses that d is relevant to q. To adhere to the notion of information retrieval as uncertain inference, probabilistic datalog (pDatalog) can be applied for the calculation of the retrieval weights (refer to [11] for further details). pDatalog uses function-free Horn clauses and can cope with probabilistic facts and rules. This way, we can assign probabilities to facts, e.g. the weight of indexterm(d,t) might be estimated using a normalisation ntf(t,d) of the frequency of t in d. The weight of indexterm(d,t) is then the probability that d can be indexed with t. The probability of acc(d,a) can be interpreted as the probability that a user reads document d and from there also moves to a. The estimation of this probability might depend on certain values like the author of a or the total number of annotations referring to d. Based on such probabilistic facts, pDatalog calculates the probability that an event occurs as follows: Assuming that n events are independent, pDatalog computes the probability of the combination of these events as
Consider a document d and a corresponding annotation a that are represented as a set of index terms with corresponding term weights; this can be expressed in pDatalog using probabilistic facts, e.g.:
0.5 indexterm(d,information) which means that the term weight of "information" in d is 0.5, etc. Consider that we access each annotation with probability 0.8, so we get 0.8 acc(d,a). Having the query q="information retrieval", the query is represented by the facts
qterm(q,information). (If no probability is given, we assume 1.) Applying the rules above, we get
We can also introduce probabilities for qterm(q,t), e.g., by taking the normalised inverse document frequency (ntf) of t. This way, we get a tf x idf-like weighting scheme in the model above. 2.3 Discussion SearchTwo different scenarios can be identified:
2.3.1 Searching for Relevant Annotations
Feature-based indexing approach
Logic-based retrieval approaches
and state that there is a positive or negative link, respectively, between b and a. Rules 1 and 2 exploit the positive evidence they get from the document and the annotation thread, respectively, while the third rule uses negative evidence to infer that the annotation is not relevant to the query. By possibly inferring r(q,a) and !r(q,a) for an annotation a, we gain inconsistent knowledge. To cope with this, we need four-valued logics introducing new truth values besides true and false, namely inconsistent and unknown. Furthermore, we have to assume an open world, which means missing evidence for r(q,a) does not imply !r(q,a). Four-valued probabilistic datalog is a suitable means to deal with these requirements [18]. A possible realisation of the model above with four-valued probabilistic datalog is shown in [9]. An open research question is the categorisation in positive or negative link types if this information is not given explicitly. Machine-learning techniques for a corresponding classification, similar to sentiment classification [17] might be applied to estimate the probability that an annotation is positive or negative and thus provide probabilities for pos_link and neg_link, respectively. Another possible retrieval function is based on the assumption that merely the fact that annotations refer to parts of the annotated object can be interpreted that these parts are important, even if the annotations are negative (otherwise users would not spend time to annotate them). For an annotation a, we look at the parts p of a that were annotated by some annotation b (i.e., p is element of AOb)2 . We call b a highlight annotation of a in this case. We find this situation in email discussions, where users usually quote some passage from the previous message and write some comment about it. This comment can be seen as an annotation, while the quoted passage marks the part of the previous email the annotation refers to. As discussed before, any passage p of a with p element of and b is seen as a separate digital object, and all these passages p provide a context for the annotation. A possible retrieval strategy is taking the relevance of these passages w.r.t. the query into account, yielding
part_of(a,p)if p is a part of a and refers_to(b,p) if p is element of AOb. It is obvious that p contributes to r(q,a) in two ways – either by being part of a and thus directly contributing to r(q,a), or via r(q,p). p thus does not introduce new terms, but decreases the uncertainty that a might be relevant w.r.t. the query. Annotations are closely connected to the object they annotate, so the content of these objects is also a context to determine the relevance of an annotation a. Assertions in annotations might not be understandable without considering the context in which they were made. Examples are again email discussions, where one (sometimes) has to read the quoted text in order to understand what an email is about. We thus have to consider if the object the annotation belongs to is relevant to the query, which might imply that the annotation is relevant itself:
In the above, considers(a,p) describes the fact that the passage p is actually considered and not neglected when reading a. P(considers(a,p)) is thus the degree to which the context given by the referred passage influences the retrieval weight. It should be noted that the models proposed here can be adapted to the problem of document search described in Section 2.2. 2.3.2 Relevant Annotation Threads and Best Entry PointsIn a discussion, a single annotation might not be sufficient to satisfy a user's information need. As an example, when the user is looking for pros and cons about a specific topic, usually one single annotation will not contain all relevant information. The information the user seeks is probably scattered among several discussion articles. To satisfy his or her information need, the user has to read parts of annotation threads where the pros and cons are discussed. Therefore, the system should not return a ranked list of annotations, but provide hints for the user regarding relevant subthreads and provide the user with suitable entry points into the discussion. The idea is to post-process the retrieval status value of annotations, as it is calculated by the means discussed in Subsection 2.3.1, and find suitable ways to identify relevant subthreads and best-entry points. 2.4 EvaluationAll proposed retrieval approaches have to be evaluated w.r.t. their retrieval effectiveness. In particular, the following steps have to be performed:
3 Related WorkSince an annotation thread can be seen as a hypertext, annotation-based retrieval has a strong relation to Hypertext Information Retrieval (HIR) [4]. An example numeric HIR algorithm that is similar to the logic-based approaches proposed here is the spreading activation approach proposed by Frei and Stieger [7]. This approach also incorporates typed and negative links. One interesting feature-based approach for discussion search is reported in [20] by Xi et al. They define several content, thread-tree and author features. Their results show that using the thread context for discussion search improves retrieval effectiveness. Xi et al. neglect quotations from previous messages. Golovchinsky et al. use annotations for relevance feedback by only considering highlighted terms instead of whole relevant documents for document search [12]. Experiments show a gain in retrieval effectiveness against classic relevance feeback. Fuhr and Rölleke [18] use four-valued probabilistic datalog for the retrieval of structured documents. An open issue is how to determine whether a comment is positive or negative when this information is not explicitly given. This leads to a non-topical categorization problem, which is similar to sentiment classification, where the goal is to distinguish positive from negative reviews. An interesting approach to sentiment classification, where machine learning classifiers are used, is described in [17]. The nature of annotations, their role in Digital Libraries and Collaboratories and possible annotation-based retrieval functions are discussed in [3, 1, 8, 16]. These reflections about annotations can be the basis for defining intelligent retrieval methods exploiting the annotation context. Agosti and Ferro see annotations as context for document search and describe retrieval methods based on HIR and data fusioning [2]. References[1] Maristella Agosti and Nicola Ferro. Annotations: Enriching a digital library. In Constantopoulos and Sølvberg [6], pages 88-100. [2] Maristella Agosti and Nicola Ferro. Annotations as context for searching documents. In Fabio Crestani and Ian Ruthven, editors, Information Context: Nature, Impact, and Role: 5th International Conference on Conceptions of Library and Information Sciences, CoLIS 2005, volume 3507 of Lecture Notes in Computer Science, pages 155-170, Heidelberg et al., June 2005. Springer. [3] Maristella Agosti, Nicola Ferro, Ingo Frommholz, and Ulrich Thiel. Annotations in digital libraries and collaboratories - facets, models and usage. In Rachel Heery and Liz Lyon, editors, Research and Advanced Technology for Digital Libraries. Proc. European Conference on Digital Libraries (ECDL 2004), Lecture Notes in Computer Science, pages 244-255, Heidelberg et al., 2004. Springer. [4] Maristella Agosti and Alan F. Smeaton, editors. Information Retrieval and Hypertext. Kluwer Academic Publishers, Boston et al., 1996. [5] H. Brocks, A. Stein, U. Thiel, I. Frommholz, and A Dirsch-Weigand. How to incorporate collaborative discourse in cultural digital libraries. In Proceedings of the ECAI 2002 Workshop on Semantic Authoring, Annotation & Knowledge Markup (SAAKM02), Lyon, France, July 2002. [6] Panos Constantopoulos and Ingeborg T. Sølvberg, editors. Research and Advanced Technology for Digital Libraries. Proc. European Conference on Digital Libraries (ECDL 2003), Lecture Notes in Computer Science, Heidelberg et al., 2003. Springer. [7] H. P. Frei and D. Stieger. The use of semantic links in hypertext information retrieval. Information Processing and Management, 31(1):1-13, January 1994. [8] I. Frommholz, H. Brocks, U. Thiel, E. Neuhold, L. Iannone, G. Semeraro, M. Berardi, and M. Ceci. Document-centered collaboration for scholars in the humanities – the COLLATE system. In Constantopoulos and Sølvberg [6], pages 434-445. [9] Ingo Frommholz, Ulrich Thiel, and Thomas Kamps. Annotation-based document retrieval with four-valued probabilistic datalog. In Thomas Roelleke and Arjen P. de Vries, editors, Proceedings of the first SIGIR Workshop on the Integration of Information Retrieval and Databases (WIRD'04), pages 31-38, Sheffield, UK, 2004. [10] N. Fuhr and C. Buckley. A probabilistic learning approach for document indexing. ACM Transactions on Information Systems, 9(3):223-248, 1991. [11] Norbert Fuhr. Probabilistic Datalog: Implementing logical information retrieval for advanced applications. Journal of the American Society for Information Science, 51(2):95-110, 2000. [12] Gene Golovchinsky, Morgan N. Price, and Bill N. Schilit. From reading to retrieval: freeform ink annotations as queries. In Proceedings of the 22nd International Conference on Research and Development in Information Retrieval, pages 19-25, New York, 1999. ACM. [13] Norbert Gövert, Mounia Lalmas, and Norbert Fuhr. A probabilistic description-oriented approach for categorising Web documents. In Susan Gauch and Il-Yeol Soong, editors, Proceedings of the Eighth International Conference on Information and Knowledge Management, pages 475-482, New York, 1999. ACM. [14] Kalervo Järvelin, James Allen, Peter Bruza, and Mark Sanderson, editors. Proceedings of the 27st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, 2004. ACM. [15] Gabriella Kazai, Mounia Lalmas, and Arjen P. de Vries. The overlap problem in content-oriented XML retrieval evaluation. In Järvelin et al. [14], pages 72-79. [16] Catherine C. Marshall. Toward an ecology of hypertext annotation. In Proceedings of the ninth ACM conference on Hypertext and hypermedia: links, objects, time and space - structure in hypermedia systems, pages 40-49, 1998. [17] Bo Pang, Lillian Lee, and Shivakumar Vaithyanathan. Thumbs up? Sentiment classification using machine learning techniques. In Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 79-86, 2002. [18] T. Rölleke and N. Fuhr. Retrieval of complex objects using a four-valued logic. In Proceedings of the 19th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 206-214, New York, 1996. ACM. [19] C. J. van Rijsbergen. A non-classical logic for information retrieval. The Computer Journal, 29(6):481-485, 1986. [20] Wensi Xi, Jesper Lind, and Eric Brill. Learning effective ranking functions for newsgroup search. In Järvelin et al. [14], pages 394-401. Notes1. This formalisation should be seen as a preliminary one and subject to further discussion. 2. It is an open question what it means for our scenario if annotations refer to a whole document instead of just a part of it. 3. INitiative for the Evaluation of XML Retrieval, <http://inex.is.informatik.uni-duisburg.de/2005/>. 4. TREC Enterprise Track, <http://www.ins.cwi.nl/projects/trec-ent/>. © Copyright 2006 Ingo Frommholz Top | Contents |