
|
|
|
TCDL Bulletin A Novel Approach for Compound Document MatchingMichael Springmann AbstractFuture digital libraries will not only contain pure text documents, but increasingly will hold massive amounts of compound documents that comprise many multimedia objects, e.g., texts, images, audio, and video. Already existing collections of documents, e.g., all electronic health records of one clinic can form a digital library with millions of multimedia objects and a total storage of several terabytes. It is therefore important to provide ways for effective and efficient retrieval for those collections. This paper proposes a novel approach for compound document matching using a filter-and-refinement algorithm for similarity-based retrieval within documents, which may consist of arbitrarily many objects of various media types. At the same time, this approach increases the effectiveness by establishing only semantically meaningful matches and providing greater expressiveness in queries by restricting the number of allowed matches to a single query object. 1. IntroductionDocuments in digital libraries can no longer be restricted to being plain text documents. The nature of the items we want to store in digital libraries is that they comprise several objects of various types and formats. One instance of such complex document collections for which the University for Health Sciences, Medical Informatics, and Technology (UMIT) shows strong interest in particular is electronic health records. 1.1 MotivationElectronic health records have become a very important patient-centered entity in health care management. They represent complex documents that comprise a wide diversity of patient-related information, like basic administrative data (patient's name, address, date of birth, name of physicians, hospitals, etc.), billing details (name of insurance, billing codes, etc.), and a variety of medical information (symptoms, diagnoses, treatment, medication, X-ray images, etc.). Most of these details are structurally and temporally interrelated, like a (1) particular treatment and (2) medication ordered from a (3)physician on an (4) established diagnosis from patient's (5) reported symptoms at a (6) certain date. Each item is of a dedicated media type, like structured alphanumeric data (e.g., patient name, address, billing information, laboratory values, documentation codes, etc.), semi-structured text (symptoms description, physician's notes, etc.), images (X-ray, CT, MRT, images for documentation in dermatology, etc.), video (endoscopy, sonography, etc.), time series (cardiograms, EEG, respiration, pulse rate, blood pressure, etc.), and possibly others, like DNA sequence data. State-of-the-art medical information systems aggregate massive amounts of data in patient records (e.g., [1]). Its exploitation, however, is mainly restricted to accounting and billing purposes, leaving aside most medical information. In particular, similarity search based on complex document matching is out of scope for today's medical information systems.1.2 ContributionWe believe that efficient and effective matching of patient records forms the rewarding foundation for a large application variety. Data mining applications that rest upon our patient record matching approach will foster clinical research and enhanced therapy, in general. Specifically, our proposal allows for effective comparison of similar cases to (1) shorten necessary treatments, (2) improve diagnoses, and (3) ensure the proper medication to improve patients' well-being and reduce cost. In more detail, we introduce a novel approach for matching compound documents that tackles several issues. On the one hand, we describe a query model that does not neglect the diversity of the components that form a complex document and that offers the notion of domains to express this distinction. The query model also addresses the problem of multiple occurrences of objects of the same type in the searched document. On the other hand, the proposed matching algorithms allows for efficient similarity search with interactive answering times while processing large document collections. 2. Compound Document MatchingHealth records, like any other compound multimedia document, consist of several component objects of different media types. Any digital library containing such documents should offer a query interface that provides more than just simple keyword search. One promising approach is to identify relevant documents and use them for a search for similar items. This approach is known as query-by-example (QBE) and is very common in image retrieval (e.g., [2]). More precise queries can be posed by identifying component objects of particular interest and assigning weights. But for the time being, only the unweighted case will be illustrated. In order to compute the similarity between two compound documents, it is necessary to aggregate the similarity between their composing objects. Therefore it is necessary to establish matches of corresponding media objects. Structural information stored with the compound documents might help with this task, but in general, using only this information is not sufficient, since there might be several objects that fit from one object to the other document. This is especially true in the case when multiple instances of structurally identical information are kept in one compound document – which is an absolute necessity in health records to keep track of the progress of the state of health of one patient over time. Finding these corresponding objects within large sets of objects is a computationally intensive task. A similar problem is prevalent in region-based image retrieval (RBIR).
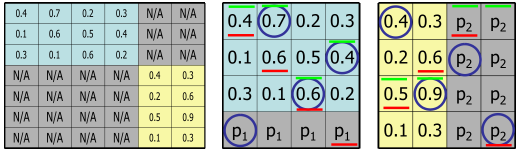
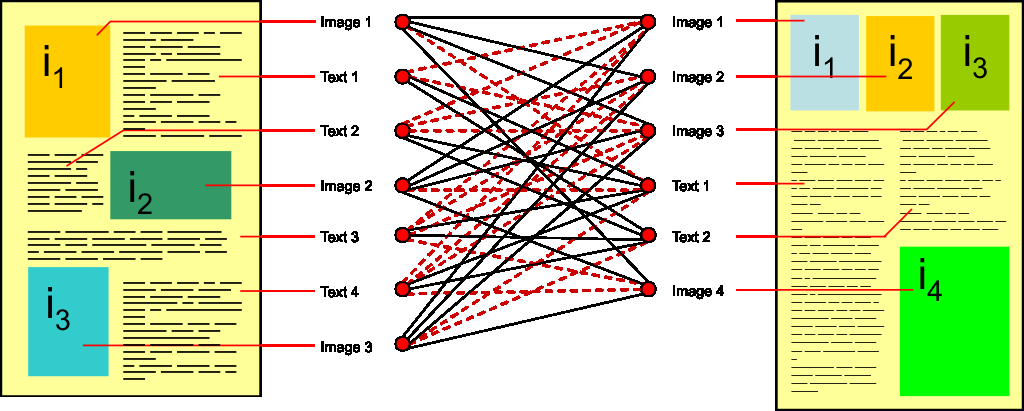
That is, regions from two images must be matched to compute an overall similarity score. In region matching, as is described in [3], images are partitioned into disjoint regions. Two images' overall similarity score is computed by finding best pairs of regions from those two images. This optimization problem of finding best pairs is a generalization of the so-called Assignment Problem. Using the Hungarian Algorithm [4], the complexity of similarity computation for two region sets is O(r3) with r being the number of regions in both sets. From a query processing point of view, a cubic complexity is unsatisfactory, restricting the applicability to small data sets and few regions. To perform this task more efficiently, [3] proposes a two-stage filter-and-refinement approach. The first stage yields a small number of candidate matches by computing computationally cheap, yet tight upper and lower bounds to the exact similarity score. The second stage invokes the exact distance function on the candidates. As the cost to compute lower and upper bounds is significantly lower than its exact counterpart, tremendous speed-ups can be achieved. In [3], authors report a factor of five in query processing time consumption. Like images can be partitioned into regions, compound documents can be divided into their component objects. Figure 1 illustrates this for two documents, consisting of seven and six objects and the resulting bipartite graph for the possible matches. Calculating the similarity of two compound documents c1, c2 must (1) establish matches between corresponding objects from both documents and (2) compute the document similarity out of the individual object similarities. 2.1 Finding Corresponding ObjectsIn contrast to region matching, compound documents may consist of objects from various domains. In Figure 1 both documents have objects of the domains text and images. Since they do not have the same number of images and texts, we would need to assign some texts to images in order to match as many as possible without assigning objects repeatedly. But how can we be sure that the text really relates to the image? To be sure, we would need a similarity function comparing texts to images. In general, no meaningful cross-domain similarity function exists, e.g., it is not feasible to match a cardiogram against a CT image of the lung. Even between objects of the same media type, a comparison can be problematic. If we think of medical imaging, DICOM files are generated via various techniques (CT, MRI, PET, etc.) that all differ in the way they represent tissues. Moreover, the screened body function and the spatial orientation of an image have an impact on the object domain, as well. Domains therefore should not be defined solely on media types, but whether there exists a similarity measurement between two objects that is meaningful to the user and appropriate for his or her query. This task is clearly related to the application area to a very high degree: If we think of medical health records, it would frequently make sense and improve the results if we distinguish domains, depending on whether one object dates back before the beginning of the relevant treatment or was created after this. For instance, medical images before and after surgery should be separated in different domains. For many medical procedures, there are also common rules for further examinations, e.g., six weeks after the treatment, a follow-up examination has to take place. This knowledge should be used to refine the granularity of domains. A good definition of the evaluated domains can be crucial to a particular application, but this can only be handled with detailed knowledge on the structure and (meta-)data of the compound documents. Tools like described in [5] may assist the user to generate rules that can be used to derive domains. The problem of defining domains for particular applications is of high importance, but it is outside the focus of this paper, which deals with compound documents more generally. Similarity of ObjectsThe similarity between any two objects is computed using an appropriate similarity function for their domain and the result is normalized to the interval [0,1], such that 1 denotes most similar and 0 not similar. We can build a similarity matrix where the rows depict objects from the compound document c1 and the columns the objects of the compared document c2. The matrix is filled with the similarity score returned by the function for the respective objects. The example with 7 objects in c1 and 6 in c2 is shown in Figure 2 (a). The value N/A indicates that no meaningful match exists. Therefore, we use domain-specific matrices instead, which contain only meaningful matches. As a base case we want to use the following assumption: Every component object of c1 should correspond to exactly one object of c2 and vice versa. That is, we assign each object to exactly one other object, which is called a complete match.
Since it is not possible to find exact matches in non-quadratic matrices, we extend the those matrices until each has as many columns as rows and fill these new fields with so-called penalty values (cf. p1 and p2 in Figure 2 b and c). In this way, we may penalize (or reward) missing counterparts in c2 to objects from c1 (and vice versa). Semantics of Matching Given the fact that we use content-based similarity functions to determine the values of the matrices, correspondence of one object to another object means that they have similar content and therefore bear similar information. The information of one compound document is distributed among its component objects. If c1 is used as a query to a digital library system and is compared to c2 and we can assign every object in c1 (which build the rows of the domains) precisely to one object with high similarity in c2, then they do not only contain similar information, but also do this to some extend in a certain structure: The information is distributed to the component objects in a similar way. For missing counterparts it is necessary to distinguish two cases:
Both of the aforementioned cases are undesirable to the user. But depending on the particular information need and the digital library used, both cannot be avoided completely. For instance, in the particular case of health record retrieval, if there is no entry about one particular decease, it does unfortunately not guarantee that the patient is not suffering from this decease or will suffer in the near future. But at least it is less likely. In contrast, additional information will most likely always be present, if there has been no pre-selection, e.g., when a database was built for one particular purpose and includes only information of high interest. Hence, a good choice of the penalty values is depending on the searched dataset, whether it represents a missing row or column, and to some extend even on the information need of the user. Another issue is whether or not to allow multiple assignments to one object, but its impact can only be explained with a clear definition of the term document similarity. 2.2 Document SimilarityDocument matching solves an optimization problem, which is on finding the maximum overall similarity of two compound documents. That is, sim(c1, c2) computes two documents' similarity out of their component object similarities. For the time being, we use the unweighted average of the objects' similarities, using a separate similarity matrix for each domain. The computationally expensive part is to maximize the overall similarity while forcing a complete match in each domain, for which we use the Hungarian Algorithm. Following [3], we use a two-stage filter-and-refinement-algorithm. In a first stage, we find a small set of candidate documents using less expensive, approximative similarity functions. The second stage invokes the costly Hungarian Algorithm on the remaining candidates. To determine the set of candidates, we employ approximative, yet tight bounds on the document similarity. That is, we introduce an upper bound document similarity simub(c1, c2) >= sim(c1, c2) and a lower bound similarity simlb(c1, c2) >= sim(c1, c2). To keep the example as simple as possible, assume p1 = p2 = 0 as penalty values of the domains.Upper Bound Similarty A valid upper bound to the document similarity is to simply choose a locally best match (maximum similarity) for each component object of the compared document (column) in the similarity matrix, as indicated in Figure 2 by green bars above the numbers. In this way, we achieve upper bounds of (0.4 + 0.7 + 0.6 + 0.4)/4 = 0.525 (domain 1) and (0.5 + 0.9 + 0 + 0)/4 = 0.35 (domain 2). To calculate the upper bound of the complete document, we have to compute the average of the similarity of the domains, so simub(c1, c2) = (0.525 + 0.35) / 2 = 0.4375. Notice that neither matches are complete, as two objects from c1 match to the same object from c2 (domain 1) with a similar situation in domain 2. Lower Bound Similarity On the contrary, any complete match is a valid lower bound. To get a tight bound, we choose again the maximum similarity for each object match, but this time enforce a complete match. In the example, this is indicated by red bars below the numbers. The lower bound might return the overall best solution, but since it also uses only local maxima, it is not guaranteed to return the global maximum. In the example, the lower bound similarity is (0.4 + 0.6 + 0.6 + 0)/4 = 0.4 (domain 1) and (0.5 + 0.6 + 0 + 0)/4 = 0.275 (domain 2). This is also known as Column-Scan Method as published in [6]. The average of the domains' lower bound similarities is simlb(c1, c2) = 0.3375. Exact Similarity Using the Hungarian Algorithm, we can compute the overall maximum for each domain. The result is indicated by blue circles around the similarity scores. For domain 1 it is (0 + 0.7 + 0.6 + 0.4)/4 = 0.425 and for domain 2 it is (0.4 + 0 + 0.9 + 0)/4 = 0.325. The overall exact document similarity sim(c1, c2) therefore is 0.375. Improvement of Estimations Notice that for the upper bound as well as for the lower bound, we could also scan each row instead of columns for maximum values. For big matrices, where the exact computation using the Hungarian Algorithm is very expensive, it is preferable to perform this additional computation to narrow the bounds. As the upper bound scanning rows would estimate the similarity as (0.7 + 0.6 + 0.6 + 0)/4) = 0.475 (domain 1) and (0.4 + 0.6 + 0.9 + 0.3)/4 = 0.55 (domain 2), we could at least safely reduce the upper bound of domain from 0.525 to 0.475 – for domain 2 we cannot achieve any improvement. Because both, scanning rows and columns, result in a valid upper bound, we can pick for each domain the smallest value and therefore refine simub(c1, c2) = (0.475 + 0.35)/2 = 0.4125. The row scan as lower bound would achieve (0.4 + 0.6 + 0.6 + 0 )/4 for domain 1, which is exactly the same solution as the row scan determined. For domain 2, the row scan would return (0.4 + 0.6 + 0 + 0), which is less than the value found using a column scan and is therefore worse as a lower bound. Hence we cannot refine the simlb for this particular example with an additional row scan. Efficient Filter-and-refinement algorithm In the first stage, a set of candidate documents is computed. Candidates are documents with an upper bound similarity simub greater than the highest lower bound similarities simlb. This can be implemented by comparing every document in the collection with the query document by (1) computing simub and if it is greater than some threshold, (2) compute simlb and update the threshold. The second stage takes the candidates in descending order of their simub and applies the expensive exact similarity computation. Therefore the candidates are kept into a priority queue. The candidate on the first position is taken from the queue, its exact similarity is computed, and the candidate is reinserted into the queue based now on this exact similarity. Whenever we pick a candidate from the queue for which we computed the exact similarity already, we know that this is the best possible match remaining in the queue and can return it as a result to the query. 3. Dealing with Multiple AssignmentsSo far, the algorithm is able to return the best results enforcing a complete match within each domain. This is very restrictive at first glance, because it does not only define the requested information, but also the form of its distribution among document objects. One possibility to relax this constraint is to set appropriate penalty values. Semantics of Penalty Values In general, a value of 0 or less would penalize a missing corresponding object rather severely. In the extreme case, where the value is set to the negative infidelity, any missing object would immediately make the document the least desirable of all candidates. So this is similar to filtering documents by specifying predicates. Another particular value of interest would be the exact average of all non-penalty matches in a domain. This is equivalent to not penalizing any missing object. Constraints on the Number of Allowed Assignments One completely different possibility is to relax the complete match criterion. That is, one could accept multiple assignments to one object depending on the particular query. It is important to distinguish between repetition of component objects of the query document and component objects of the compared document. In the first case, one object of the query document could be allowed to be assigned several times to objects in the searched document. This can be useful, if (nearly) redundant information improves the value of this document, e.g., because the document focuses more on the particular topic of interest, or in the context of health records, its information might be more reliable. But on the other hand, we may not want unlimited repetition, because repeating this information over and over again should not compensate for not offering any similar object to some other query object. So this is to some extent similar to the idea of evaluating term frequencies in text retrieval, although here we cannot simply determine whether a document contains a query object, because we are not measuring containment or exact matching, but similarity between objects. So the easiest way to cope with this property would be to set a fixed maximum value for the allowed number of assignments, e.g., at most three assignments. A simple approach to provide this functionality could repeat the row of the corresponding query object in the similarity matrix two additional times before applying the Hungarian Algorithm. But this approach lacks one desired feature, which is at least important to health records: We should not require multiple occurrences of information, because e.g., one image can show a fracture of a bone as well as two more would do. Following this approach, if we enforce a complete match with repeated rows, we might need to assign low values or penalty values in the extreme case. Hence it would be better to compute also the similarity without repetition and repeating the row only once and choose the version that achieves the highest domain similarity. This would be computational expensive and it is better if it is not done every time we match the query document to another document, but only in those cases where we can expect good results. A better approach uses the following idea: If we wanted to allow any number of row assignments, we could simply use the upper bound of the first stage of the algorithm, scanning the columns for maximal values. This provides a similarity score greater or equal to any restricted assignment on rows (whereas scanning the rows would assign each row exactly one time, but may repeat columns). On the other hand, the most restrictive useful assignment is the complete match, provided by the second stage. Hence we can use simub again as an upper bound and sim as a new lower bound. We can now extend stepwise the similarity matrix for allowing multiple assignments to any desired number and through this, relaxing the constraint without increasing the overall complexity by a great factor at once. This approach can easily be extended to also allow multiple assignments for more than one object of the query document, e.g., for all objects of one domain. We can also force a minimum number of assignments by extending the matrix for the particular object before computing the upper bound and complete match with the repeated object's row. This might be more useful in different contexts, e.g., when each document object is an extracted frame from video material. In case we want to detect video sequences and the query is defined by selecting one or more frames, we may get many false positive detections since the context of individual frames is not considered within the matching. But if we can set a limit for the minimum number of frames in the sequence that need to be similar to the query object(s), this may already reduce the number of false positive detections because frames of interest need to appear several times within the video sequence, e.g., it is part of a longer scene and not just a single frame between two scenes. Experimental results will have to show, how this added expressiveness in queries – which is to be able to specify any minimum and maximum number of allowed assignments for objects to reward higher reliability – can be exploited to achieve better results in terms of precision and recall, and whether this justifies the additional computation to determine the exact similarity. Relationships Between Query Objects The other case, allowing multiple assignments of one column, can clearly be implemented applying the above mentioned technique on the transposed matrix. In terms of semantics, this would imply that it is preferable that one object is not only similar to one object of the query document, but several. Under the assumption that the query document contains only ideal examples of the wanted objects, this will not be the case. If the assumption is not true, which – in fact – is unfortunately rather likely, then it is better to provide several examples, but also identify them as somehow related, and specify the kind of relationship they have. E.g., the user wants to search for an image and does not have an ideal example at hand. Assume the system can extract features from medical images like the position of a tumor of the lung, and the user wants to use this as a measure of similarity between two shots. The two examples that are known by the user and therefore can be provided within the query are: one image where the tumor is located in the left lobe of the lung, and another one where it is in the right lobe. Following the approach in [7], there are three different ways to combine the information that can easily be used here. If the desired ideal answer to the query would be a document containing an image that shows one tumor in the left lobe and also a tumor in the right lobe, the user could make this more explicit by specifying the relation as and for the two images in his query. One appropriate way to evaluate this would use a standard fuzzy-logic operator for and by computing the mathematical minimum of the similarity achieved by the two images for each image individually of the compared document. Another possibility would be that we actually want to express that we are interested in images where the tumor is located in the left lobe, as well as in images where the tumor is located the right lobe. The relation then would be or and the corresponding fuzzy-logic operator would use the maximum. Hence, if the compared object to either of the example images is in the query, the higher similarity will be taken for all the following computation. The third possibility, which might not often be the desired case for this particular example, is that we are most interested in images where the tumor is located between the left and the right lobe. The mathematical function to achieve this would be to take the average similarity. It is obvious that knowing what the user is interested in is crucial to provide good results. If the system would simply allow multiple assignments of one column and then, in order to determine the overall document similarity, compute the average, this would imply that the user is interested in some sort of average similarity between objects of the query document. A much better approach provides the user a simple way to express his or her information need in more detail, in particular how the objects in the query document are related to each other, as long as they should not be matched individually (as the unmodified version enforcing a complete match would do). It would also be much more efficient if the implementation would then compute the minimum, maximum, or average at the time of constructing the similarity matrix – and not at the time of evaluating the matrix to determine the best match. 4. Related WorkMuch effort has been spent on finding appropriate algorithms to match objects of identical type in various fields. For instance, information retrieval developed several models for finding text in large document collections, starting from Boolean retrieval, reaching to vector space and probabilistic models. Retrieval of inexact matches in text and coded information can be improved using thesauri or controlled vocabulary like described in [8]. Content-based image retrieval frequently employs numeric features like histograms, wavelet coefficients, Fourier descriptors, etc. to express low level image characteristics like color distribution, texture and shape properties. An overview on existing techniques for content-based image retrieval with respect to applications in medical imaging is presented in [1]. Algorithms for similarity search in sequences and time series gained attention within the last decade (e.g., [9]) in the database and data mining community. But as [10] remarks, many of the proposed algorithms are not applicable to all fields, but to a rather limited set of domains. Similarity search for sequences in the biomedical domain is widely used in sequence alignment, for which the most prominent example is BLAST [11]. Compared to similarity on individual object domains, complex multimedia documents that comprise many different media objects have received little attention, so far. The main focus has been on compound documents containing images and texts. [12] provides a model for querying documents according to their structure, text, and image components. [13] proposes a query language for structured multimedia documents, named POQLMM, which can include audio and video content and uses conversation functions for combination with text retrieval. Both approaches offer a query language, in which the structure of the documents that should be retrieved can be specified in much detail. But it is neither possible easily to prohibit multiple assignment of objects to several query objects nor to specify elegantly that multiple reoccurrences of one query object would be desirable. Especially in the medical domain, many systems, like CBIR2 [14] for instance, even have the structural restriction that each document can contain only one text object and exactly one image. For this reason, their usage for general digital libraries of compound documents are very limited. Other approaches generate textual annotations that are queried based on keywords. For this purpose, CIMWOS [15] uses audio, text, and image processing and [16] uses object recognition and spatial orientation. These approaches cannot provide the full query-by-example functionality that might be needed if we want to perform nearest neighbor search. 5. Summary and OutlookThis paper proposes a novel approach to compound document matching. Specifically, an existing filter-and-refinement algorithm from region-based image retrieval has been adapted to cope with fundamental concepts of similarity search in digital libraries of compound documents. The notion of domains has been introduced to incorporate the heterogeneous structure of documents, as can be experienced with complex patient records. In terms of query processing, the concept of domains is exploited to exclude cross-domain matchings of component objects. Because computing the similarity for a given matrix is the most time-consuming part of document matching, noticeable speed-ups as opposed to the native algorithm can be achieved. In addition to that, the proposed approach offers the user more expressiveness in his or her queries, because the approach is able to handle any constraint on the number of assignments of query objects. For the time being, this paper has classified compound documents as instances of plain multimedia documents. Precisely, matching rests upon equally weighted incoherent component objects. Future extensions of our matching approach must incorporate a complex query model that allows the adjustment of influence of component objects by assigning individual weights, but also covers temporally and structurally interrelated content, as is the case in any health record. Moreover, future enhancements of the query model are required to enable, in more depth, predicate-like conditions on the result set and, through this, offers support for both rather vague and very precise queries. All these ideas have to be tested and evaluated thoroughly using meaningful datasets. The collections and queries used for the ImageCLEF retrieval track [17] are likely to form a good starting point for this. About the AuthorMichael Springmann is currently working on his Ph.D. in Medical Informatics at the University for Health Sciences, Medical Informatics and Technology (UMIT) in Hall, Tyrol, under the supervision of Prof. Hans-Jörg Schek. Michael is working in the Institute for Information Systems, which deals with the highly interconnected information in a pervasive computing environment, i.e., with the infrastructure for information space, called 'hyperdatabase network' that is especially appropriate for e-health applications. A hyperdatabase network is, briefly summarized, a synthesis of database technology, peer-to-peer computing and grid infrastructure [18]. The author's main research focus is on reusable building blocks for intelligent search in compound documents. He received his MSc in Computer Science in 2003 from Eastern Michigan University, Ypsilanti, MI, USA, and holds an MSc in Computer Science from the Fachhochschule Karlsruhe - University of Applied Sciences, Karlsruhe, Germany. References[1] Müller, H., Michoux, N., Bandon, D., Geissbuhler, A., A review of content-based image retrieval systems in medical applications – clinical benefits and future directions. International Journal of Medical Informatics 73 (2004) 1-23. [2] Flickner, M., Sawhney, H., Niblack, W., Ashley, J., Huang, Q., Dom, B., Gorkani, M., Hafner, J., Lee, D., Petkovic, D., Steele, D., Yanker, P., Query by image and video content: The qbic system. Computer 28 (1995) 23-32. [3] Weber, R., Mlivoncic, M., Efficient region-based image retrieval. In CIKM '03: Proceedings of the twelfth International Conference on Information and Knowledge Management, ACM Press (2003) 69-76. [4] Knuth, D.E. In The StanfordGraph Base. ACM Press (1993) 41-43. [5] Little S., Hunter J., "Rules-By-Example - A Novel Approach to Semantic Indexing and Querying of Images", In ISWC 2004: Proceedings of the third International Semantic Web Conference, Springer (2004) 534-548. [6] Kurtzberg, J.M., On approximation methods for the assignment problem. J. ACM 9 (1962) 419-439. [7] Fagin, R., Combining Fuzzy Information: an Overview. ACM SIGMOD Record J 32 (2002) 109-118. [8] French, J.C., Powell, A.L., Gey, F., Perelman, N., Exploiting a controlled vocabulary to improve collection selection and retrieval effectiveness. In CIKM '01: Proceedings of the tenth international conference on Information and knowledge management, ACM Press (2001) 199-206. [9] Agrawal, R., Faloutsos, C., Swami, A.N., Efficient similarity search in sequence databases. In FODO '93: Proceedings of the 4th International Conference on Foundations of Data Organization and Algorithms, Springer (1993) 69-84. [10] Keogh, E., Kasetty, S., On the need for time series data mining benchmarks: a survey and empirical demonstration. In KDD '02: Proceedings of the eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM Press (2002) 102-111. [11] Altschul, S.F., Gish, W., Miller, W., Myers, E.W., Lipman, D., Basic local alignment search tool. Journal of Molecular Biology 215 (1990) 403-410. [12] Meghini, C., Sebastiani, F., Straccia, U., Modelling the retrieval of structured documents containing texts and images. In ECDL '97: Proceedings of the First European Conference on Research and Advanced Technology for Digital Libraries, Springer (1997) 325-344. [13] Henrich, A., Robbert, G., Combining multimedia retrieval and text retrieval to search structured documents in digital libraries. In Proceedings of the First DELOS Network of Excellence Workshop on Information Seeking, Searching and Querying in Digital Libraries, (2000). [14] Antani, S., Long, L.R., Thoma, G.R., A biomedical information system for combined content-based retrieval of spine x-ray images and associated text information. In Proceedings of the Indian Conference on Computer Vision, Graphics, and Image Processing (ICVGIP 2002), (2002). [15] Papageorgiou, H., Protopapas, A.: Cimwos, A multimedia, multimodal and multilingual indexing and retrieval system. In Proceedings of the 4th European Workshop on Image Analysis for Multimedia Interactive Services, World Scientific Publishing Co. (2003) 563-568. [16] Rabitti, F., Savino, P., An information-retrieval approach for image databases. In Proceedings of the 18th International Conference on Very Large Data Bases, Morgan Kaufmann Publishers Inc. (1992) 574-584. [17] Clough, P., Müller, H., Sanderson, M., The clef 2004 cross-language image retrieval track. In CLEF 2004: Proceedings of the Cross-Language Evaluation Forum Workshop, (2004). [18] Schek, H.J., Schuldt, H., Schuler, C., Weber, R., Infrastructure for Information Spaces. In Proceedings of the 6. East-European Conference on Advances in Databases and Information Systems (ADBIS'2002), Springer, (2002) 23-36. © Copyright 2006 Michael Springmann |

{kind=link}
{kind=link}