|
|
|
TCDL Bulletin Personnalisation Services for Digital LibrairiesHanen Belhaj Frej AbstractIn this paper a subscription system for digital libraries is considered that offers personalized services to users. The digital library provides access to documents whose content is described using terms from a predefined taxonomy that is a set of terms together with a subsumption relation between terms. The same taxonomy is also used to express the user's profiles that represent the user's preferences on which rely the personalization services. Three kinds of services are investigated in my doctoral research: alert services, trails construction and document customization. The focus of this paper is alert services. 1. 1. Introduction/ MotivationDigital Libraries are becoming more and more widely spread, the volume of information they manage is increasing very rapidly, and the number of people using them is growing at a tremendous rate. As a consequence, the basic services provided by digital libraries today are no longer sufficient to satisfy all users' expectations. Nowadays there is a need for digital libraries to move from being passive to being more proactive in providing and customizing information for each user. This is what is commonly known as "personalization services" [16]. Personalization can be defined as the way in which information and services can be tailored in a specific way to match the unique and specific needs of an individual user or a community of users. This is achieved by adapting the presentation and/or the services provided to the user by taking into account the user's profile/preferences [16,19]. For my doctoral research, I consider three main aspects of personalization in digital libraries:
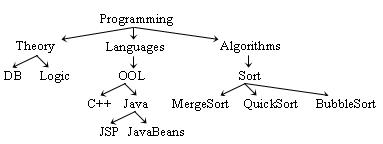
So far, the trails construction and document customization services have not been deeply investigated. In this paper, we are focusing on the alert services. 2. Related workInterest in Digital Library research expanded rapidly through the 1990s. But researchers became interested in Digital Library Personalization only a few years ago. The first personalisation service considered in my doctoral research is the Alert Service also called Recommender Service, Notification Service. In fact, the interest in alert services has grown rapidly in recent years, mainly due to their use in various Web applications. Indeed, alert services can help not only in reducing the number of accesses to the library by its users, but also in increasing their satisfaction. Alert services rely on knowledge of user interests found in user profiles. As the number of users is expected to be very large and the amount of published information is increasing at very high rates, alert services have become a crucial functionality in digital libraries. In particular, the alerting process, which consists in matching changes with user profiles, has to be as efficient as possible [3,7,8,11,13,15,21,22]. This is achieved mainly by using filtering techniques. Two kinds of filtering are commonly distinguished, Collaborative Filtering [10,19] and Content-based filtering [5,14]. Our approach is a Content-based filtering approach. Several data structures and so far algorithms have been proposed to optimize the filtering process, mostly in the area of relational databases and queries. They represent the subscriptions and the descriptions by sets of predicates, where a predicate is a triplet: (attribute, operator, value); and the operator may be ≤ or ≥ or =. Two main techniques are used in this context. The first one relies on a two-step approach: first the predicates are evaluated with respect to the event's values, and second the matching subscriptions are determined by counting the number of satisfied predicates. Fabret et al. [8] use indexing of equality predicates to speed up the matching of atomic formulas and clusters subscriptions to minimize cache failure. A similar approach is used in Pereira et al. 2000a [21] and in Pereira et al. 2000b[22] In the SIFT system [24] the subscriptions are composed of a set of weighted keywords. The matching algorithm is based on techniques of similarity computation. These techniques do not apply to our problem: we do not have "attributes", and the indexing of equality predicates does not extend to the subsumption relation. The second technique works also in two steps. The first step organizes the subscription directory in a special structure (it can be a tree, or a graph), while the second step uses this special structure to filter the incoming events. For the Elvin Publish/subscribe system, Gough and Smith [11] present an algorithm translating the subscriptions into a tree. Subscriptions are represented by leaf nodes. The other nodes of the tree represent predicate tests. A subscription can correspond to several paths in the tree. When an event occurs, there is a single path to follow to find the matching subscriptions, which means that every predicate is tested only once but it is stored in a redundant way, leading to a combinatorial explosion of its occurrence and by consequence, to a combinatorial explosion of the total number of nodes. This is not the case with our tree structure, since the number of nodes is in the worst case 2*|S|, where |S| is the number of subscriptions. Furthermore, the maintenance of the tree structure used by Gough and Smith [11] is very costly compared to the approach described here. In fact, it is suggested that the tree be reconstructed from scratch for every modification of the subscriptions. The algorithm presented in Aguilera et al. [3] is also based on a tree structure where subscriptions are stored in the leaves and each non-leaf node represents a predicate comparison. Again the space used for this approach is very important: each new subscription adds K+1 nodes where K is the number of predicates in the new subscription. The matching algorithm traverses the tree in a depth-first order, several paths may have to be followed to find the matching subscriptions for an event, and each predicate is evaluated many times. Moreover the structure is suitable only for equality tests. A similar structure and filtering algorithm are proposed in Campailla et al. [7]. A combination of collaborative filtering and content-based filtering is also possible [4,15,18]. In summary we are not aware of a publish/subscribe technique that considers a simple keyword-based query language and a subsumption relation over the terms. Compared to other works in related areas, the solution proposed in this paper presents a reasonable storage cost (at most twice the number of subscriptions) and achieves a nice trade-off between the performance of both subscription (insertion in the structure) and notification (search in the structure). The remainder of this paper is organized as follows. In Section 3, I first recall some preliminary definitions from Rigaux and Spyratos [23] regarding taxonomies and document descriptions. In Section 4, I present a personalization service and define the basic concepts of its model, namely profiles and events. Next I focus on the notification process, which informs users whenever an event matches their profiles, and present experimental results. Section 6 offers some concluding remarks and suggestions for future research. 3. Preliminary DefinitionsIn this paper, we consider a network of authors, or document providers, willing to share their documents with other authors and/or document users. This sharing is supported by a digital library that acts as a mediator, indexing all shareable documents so that users can access them transparently. The documents reside at their providers' repositories, not in the library. For a document to be shareable, its author must submit to the library two items: the document's URI and the document's content description. The set of pairs (URI, Description) is what we call the Document Directory. Document content descriptions are built based on a controlled vocabulary, or taxonomy, to which all providers adhere. A taxonomy consists of a set of terms together with a subsumption relation between the terms. Definition 1 (Taxonomy). A taxonomy is a pair (T, p) where T is a terminology, i.e., a finite and non-empty set of terms, and p is a reflexive and transitive relation over T, called subsumption. An example of a taxonomy is the well known ACM Computing Classification System [2]. Figure 1 shows an example of a taxonomy:
In order to make a document sharable, its author must provide the document's URI and the document's content description. Users can judge whether a document matches their needs based on the document's content description. We define this description to be just a set of terms from the taxonomy and require that no term in the description is subsumed by another term. Definition 2 (Description). Given a taxonomy (T, p), we call description in T any set of terms from T.
A description D can be redundant if some of the terms it contains are subsumed by other terms. For example, the description D = {
Definition 3 (Reduced Description). A description D in T is called reduced if for any terms s and t in D, s
Following the above definition, one can reduce a description in (at least) two ways: removing all but the minimal terms, or removing all but the maximal terms. In this paper we adopt the first approach, i.e., we reduce a description by removing all but its minimal terms. The reason for this choice lies in the fact that by removing all but minimal terms, a more accurate description will be obtained. This should be clear from the previous example, where the description { Definition 4 (Reduction). Given a description D in T we call reduction of D, denoted reduce(D), the set of minimal terms in D with respect to the subsumption p. A query is either a single term or a Boolean combination of terms, as stated in the following definition. Definition 5 (Query Language). A query over ( T) is any Boolean combination of terms from T:
To define the answer to a query we need the notion of extension of a term t, denoted Ext(t), and defined as the set of document ids (i.e., URIs) such that (id,t) is in the document directory. Definition 5 (Query Answer). The answer to a query q, denoted ans(q), is a set of documents defined as follows, depending on the form of q (refer to definition 4):
Case 1: q is a single term t, i.e., q = t, then ans(t) = {Ext(s)| s p t} begin Case 3: q is the empty query, then ans(ε)=∅ 4. Alerting4.1. The User Profile
Intuitively, a user profile is a statement by the user as to what his preferences are in terms of document content. As such, a profile can be defined by a query over the library taxonomy (T, p), using the query language seen earlier. Consider for example the following query: (OOL∧ This query, seen as a user profile, expresses the fact that the user is interested in documents dealing with either "object oriented languages" and "sorting" but not "databases", or in documents dealing with "theory". In this paper, we focus attention on profiles that can be expressed as conjunctive queries without negation.
In what follows, we represent a profile by a set of terms. Note that this is only possible because a profile is a conjunctive query, and therefore no ambiguity arises from this representation. For example, the profile Definition 6 (User Profile). A user profile P is the set of terms of a conjunctive query over T.
As for descriptions, a profile P can be redundant if some of the terms it contains are subsumed by other terms in the profile. For example, the profile P = { We shall limit our attention to minimal profiles reduction (we remove all but the minimal terms from P), because intuitively, they describe the user preferences as precisely and as economically as possible.
Definition 7 (Reduced Profile). A profile P is called reduced if for any terms s and t in P, s Since the profile P of a user u is defined as a query, the set of documents in the library that interest u is the query result, ans(P). We assume that the system maintains a user directory U, i.e., a set of pairs (u,P) where u is a user and P the profile of u. Creation and maintenance of the user directory is done by having each user subscribe to one or more terms of the taxonomy. 4.2. The notification processThe notification process consists of alerting users whenever a document whose description matches their profile is registered, deleted or modified in the document directory. We call event such an update of the document directory. To update a document in the library, we need the document identifier and its description. Definition 8 (Event). An event e =(id,D) consists of the addition, the removal or the modification of a document id described by D. Intuitively, given an event e, any user u whose profile matches the description in e must be notified. This is defined, more precisely, as follows: Definition 9 (Notification). Let e(id, D) be an event affecting a document id with description D. Then notify(e) is the set of users defined as follows: Notify(e) = {(u, P) ∈U | id ∈ ans(P)} Computing notify(e) is an interesting and original problem. Indeed, the traditional approach consists of computing the answer to a given query q whereas we must here find the set of queries whose result is affected by an update operation. This problem was considered in Bollacker et al. [6] and Renda and Straccia [19]. The approach described in this paper differs from other approaches in that it uses the partial order between the terms of the taxonomy in order to organise the profiles in a graph structure. This makes it possible to reduce – in a significant way – the useless accesses to profiles not concerned by the notification process, thus optimizing this process. Example 1. Consider the following example
Then any changes on id, for i=1, ...,3 must be notified to ui. (u4 and u5 will not receive this notification.) There is a straightforward filtering algorithm to compute notify(e): scan the user directory U, and for each pair (u,P), check whether the updated document belongs to the answer of P, if yes, inform u. This trivial filtering algorithm is optimal in the worst case, i.e., when all users are interested in the event. Unfortunately, this is almost never the case, and this solution is likely to be very costly in those situations where we have a large number of users and profiles, in a library supporting a high ratio of updates. In practice, one might expect that only a few users would be interested in an event, and it would be good to devise an algorithm that permits reducing useless access to profiles that are not concerned by the notification. Such an algorithm is presented in the next section. 4.3. The profiles graph
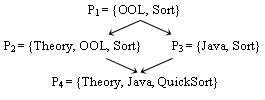
The approach advocated here relies on the following intuition: if a user u is to be notified after an event e, then all users with "more general" profiles than that of u must be notified as well. For instance, in the above example, any event e that triggers a notification to u2 (u2.P= The intuition of "more general" is formally expressed by the Refinement Relation on profiles defined below: Definition 10 (Refinement Relation). Let P1 and P2 be two profiles. We say that P1 is finer than P2 denoted P1 ≡ P2, if ∀ t ∈ P2, ∃t' ∈ P1 such that t' p t Intuitively, refining a profile can be seen as creating tighter matching constraints. There exist two possible ways of doing so: by simply adding conjunctively some terms to a profile, or by replacing a term with one of its descendants in the taxonomy. Some examples follow.
The profile P1 = {
A query can be refined through term subsumption. Therefore P1 is also refined by P3= {
Finally it is worth mentioning that a profile can be the refinement of several other profiles. For instance referring to Figure 2, P4 = {
It is easily seen that ≡ is a partial order over (reduced) profiles. We can exploit this relation as follows: if an event e does not match the profile P1, it cannot match P2, P3 or P4. Therefore, one initially evaluates the event with regard to P1. If, and only if, the matching is successful, the evaluation must be carried out for both P2 and P3. Finally, if this latter evaluation is successful for either P2 or P3, the matching with P4 has to be considered. It is expected that this strategy saves a lot of computations, because matching attempts with P1 will fail for most of the events, thereby avoiding many useless comparisons with all the queries that refine P1. This allows organizing the user directory as follows:
As has already been said, if a user u is to be notified after an event e, then all users with "more general" profiles than that of u, must be notified as well. We offer the following proposition. Proposition 1. Let e (id, D) be an event. Then, if a profile P matches e and P ≡ P' than P' matches e. 5. The Matching processFrom the profiles graph, a top-down approach can be adopted to solve the notification problem, based on the following remark: if an event does not match a profile P, then we know that it will not match any of the profiles that refine P (the children of P in the profiles graph). Note that it isn't necessary to represent the whole graph of the refinement relation. Instead the goal is to construct a spanning tree that minimizes the cost of the maintenance of the profiles structure. Moreover, profiles can be added or removed dynamically. We must therefore design an incremental algorithm to maintaining the tree. 5.1. The maintenance of the profiles tree5.1.1. Insertion of a new profileThe algorithm constructs incrementally a tree Tp of profiles. The insertion of a new profile P consists in selecting (finding) a candidate parent for P. Candidate parents selection: A node N in Tp is a candidate parent for P if the following conditions hold:
A top-down traversal of the tree allows getting the entire set of the candidate parents. But we stop the process when we find the first candidate parent. 5.1.2. Removal of a profileA profile may have to be removed either explicitly (user's choice) or implicitly (timeout). Removing a profile P from a profiles tree is a trivial operation. Two cases occur:
5.2. The matching algorithmWhenever a new event e arrives, the algorithm scans the graph top-down, starting from the root of the tree. The main procedure, Match(N, e), takes as input a node N and an event e.
6. Experimental ResultsWe analyze the behaviour of our tree structure, called Tmatch and compare it with the following competitors:
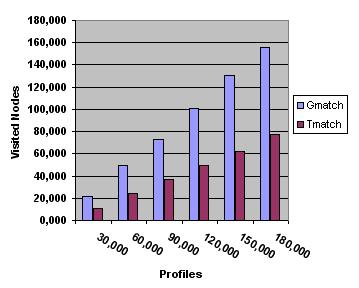
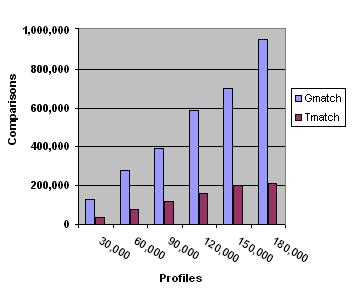
The impact of the number of users who registered a given profile P is neutral, because once a profile that matches an event is found, all the notification variants (Nmatch, Tmatch and Gmatch) merely scan the bucket of users, sending a notification to each. For clarity we ignore the cost of this specific operation in the report of our experiments, and focus on the cost of finding the set of relevant profiles. The evaluation cost is measured with respect to the following indicators: (i) number of terms comparisons, and (ii) the number of nodes visited. We successively analyze the two major operations: the insertion of new profile (comparisons made between Gmatch and Tmatch performances) and the search of the profiles that match an event (Nmatch, Tmatch and Gmatch). 6.1. Experimental settingsThe structure has been implemented in Java on a PentiumIV processor (3,000MHz) with 1,024MB of main memory. The implementation conforms to the specifications given in the previous section. Our experimental setting simulates a Digital Library storing a set of scientific documents described by terms from the ACM Computing Classification System [2] taxonomy. The taxonomy contains 1,316 terms, and its maximal depth is 5. Also implemented was a profiles generator. The generator takes as input the average size (number of terms) of the profiles, the standard variation, and the cardinality of the profiles set. Each profile is generated as follows: the generator randomly picks up a term and includes this term in the profile. The process iterates until the profile contains the required number of terms. Generated profiles are reduced: newly generated terms that subsume or are subsumed by one of the terms of the current profile are ignored. Several sets of distinct profiles were produced, with a cardinality ranging from 30,000 to 180,000. 6.2. Cost of insertionsThe cost of an insertion for the Nmatch approach is negligible, since it consists only of an insertion in a linear structure, performed in constant time. We focus therefore on the comparison of Gmatch and Tmatch. Figure 3 and Figure 4 show the cost of inserting a profile in an existing profiles tree, for different profiles datasets. We measure the number of nodes visited by the insertion algorithm (Figure 3), and the number of terms comparisons (Figure 4). As expected, the insertion of a new profile under only one candidate parent reduces the number of the comparisons needed for this operation.
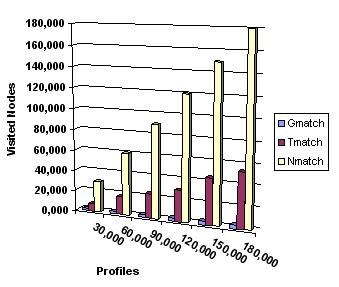
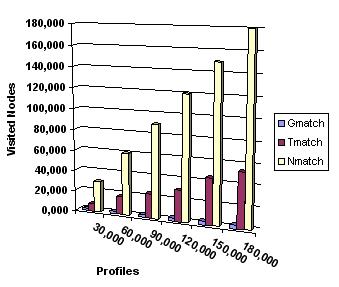
6.3. Cost of notificationsWe now turn our attention to the notification process. The results obtained for the three solutions Nmatch, Gmatch, Tmatch are given in Figure 5 and Figure 6 for our 6 profiles datasets. We compare both the average number of nodes visited (Figure 5) and the average number of terms comparisons (Figure 6) (the latter being more representative of the actual cost) for processing a single event (note that an event generates several notifications in general). For the naive solution, the number of visited nodes is equal to the number of profiles.
The curves of Figures 5 and 6, show that the Gmatch solution has better notification performances than the Tmatch. This is explained by the average fanout (number of children) which is very large for the Tmatch solution due to the insertion of new profiles under the "first" candidate parent. This led to an unbalance of the tree. To cope with this disadvantage of the tree solution, a new solution is being investigated derived from the Tmatch solution based on the insertion of "virtual" profiles that permit clustering sub-sets of other already existing profiles and reducing the average fanout of the nodes. Experiments for the evaluation of this approach are underway, and the results obtained so far seem to confirm the theoretical part. 7. Issues for discussionIn this paper I proposed a formalization of the notification process in a digital library. The central tool of the proposed model is a simple hierarchy of terms (taxonomy) that is used both for document description and for profiles definition. The main contribution of this approach is the organization of the users profiles into a graph structure that allows minimizing the cost of the notification process. Experiments conducted so far seem to confirm this result. The next step of this work is to introduce a preference function on the terms of each profile. This aims to sort scheduled notifications. The second part of my doctoral research is going to be the investigation of the best way to use profiles for the construction of trails. References1. SpringerLink. <http://www.springerlink.com/>. 2. The ACM Computing Classification System. <http://www.acm.org/class/>. 3. Marcos Kawazoe Aguilera, Robert E. Strom, Daniel C. Sturman, Mark Astley, and Tushar Deepak Chandra. Matching events in a content-based subscription system. In Symposium on Principles of Distributed Computing, pages 53-61, 1999. 4. Justin Basilico and Thomas Hofmann. Unifying collaborative and content-based Filtering. In Proc. of the Intl. Conf. on Machine Learning ICML, page 9. 2004. 5. Chumki Basu, Haym Hirsh, and William Cohen. Recommendation as classification: using social and content-based information in recommendation. In Proc. of the natl. conf. on Artificial intelligence/Innovative applications of artificial intelligence, pages 714-720, 1998. 6. Kurt Bollacker, Steve Lawrence, and C. Lee Giles. A system for automatic personalized tracking of scientific literature on the web. In Proc. Of the ACM Conf. on Digital Libraries, pages 105-113, 1999. 7. Alexis Campailla, Sagar Chaki, Edmund M. Clarke, Somesh Jha, and Helmut Veith. Efficient filtering in publish-subscribe systems using binary decision. In Proc. of the Intl. Conf. on Software Engineering, pages 443-452, 2001. 8. Françoise Fabret, H. Arno Jacobsen, François Llirbat, Joao Pereira, Kenneth A. Ross, and Dennis Shasha. Filtering algorithms and implementation for very fast publish/subscribe systems. In Proc. of the Intl. Conf. on Management of Data (SIGMOD), 30(2):115-126, 2001. 9. Daniel Faensen, Lukas Faulstich, Heinz Schweppe, Annika Hinze, and Alexander Steidinger. Hermes: a notification service for digital libraries. In Proc. of the Joint Conference on Digital Libraries, pages 373-380, 2001 10. David Goldberg, David Nichols, Brian M. Oki, and Douglas Terry. Using collaborative filtering to weave an information tapestry. Communications of the ACM, 35(12), 1992. 11. John Gough and Glenn Smith. Efficient recognition of events in a distributed system. In Proc. of the Australasian Computer Science Conference, 1995. 12. Michael Guppenberger and Burkhard Freitag. Intelligent creation of notification events in information systems: concept, implementation and evaluation. In Proc. of the Intl. Conf. on Information and Knowledge Management, pages 52-59, 2005. 13. Eric N. Hanson, Moez Chaabouni, Chang-Ho Kim, and Yu-Wang Wang. A predicate matching algorithm for database rule systems. In Proc. of the Intl. Conf. on Management of Data, pages 271-280. 1990. 14. Patricia Y. Hsieh, Henry M. Halff, and Carol L. Redfield. Four easy pieces: development systems for knowledge-based generative instruction. Intl. Journal of Artficial Intelligence in Education, 10:1-45, 1999. 15. Zan Huang, Wingyan Chung, Thian-Huat Ong, and Hsinchun Chen. A graph-based recommender system for digital library. In Proc. of the Joint Conference on Digital libraries, pages 65-73. 2002. 16. Jamie Callan, Alan Smeaton, et al. Personalisation and recommender systems in digital libraries. Joint NSF-EU DELOS working Group Report, 2003. <http://www.dli2.nsf.gov/internationalprojects/working_group_reports/personalisation.html>. 17. Albert Ip and Ric Canale. Supporting collaborative learning activities with SCORM. In Proc. of EDUCAUSE in Australasia, 2003. 18. Marko Balabanovic and Yoav Shoham. Fab: content-based, collaborative recommendation. Communications of the ACM, 40(3):66-72, 1997. 19. M. Elena Renda and Umberto Straccia. A personalized collaborative digital library environment: a model and an application. Information Processing and Management, 41(1):5-21, 2005. 20. Tom Murray. Authoring intelligent tutoring systems: An analysis of the state of the art. Intl. Journal of Artificial Intelligence in Education, 10:98-129, 1999. 21. Joao Pereira, Françoise Fabret, Francois Llirbat, Radu Preotiuc-Pietro, Kenneth A.Ross, and Dennis Shasha. Publish/subscribe on the web at extreme speed. In Proc. of the Intl. Conf. on Very Large Data Bases (VLDB), pages 627-630, 2000a. 22. Joao Pereira, Françoise Fabret, Francois Llirbat, and Dennis Shasha. Efficient matching for web-based publish/subscribe systems. In Intl. Conf. on Cooperative Information Systems, pages 162-173, 2000b. 23. Philippe Rigaux and Nicolas Spyratos. Metadata inference for document retrieval in a distributed repository. In Proc. of the Asian Computing Science Conference, pages 418-436, 2004. 24. Tak W. Yan and Hector Garcia-Molina. The SIFT information dissemination system. ACM Transactions on Database Systems, 24(4):529-565, 1999.
© Copyright 2007 Hanen Belhaj Frej Top | Contents |