|
|
|
TCDL Bulletin Model Design of User Interfaces for Multilingual Digital LibrariesJolanta Mizera-Pietraszko AbstractThe objective of this study is to design a model of a user-friendly interface that exploits a multilingual digital library collection to its full potential. On the basis of this model an overview of French and English information retrieval systems from some digital libraries is presented. The evaluation of the libraries analyzed relies on certain usability criteria. This study shows the importance of both multilingualism and other features in designing an interface that fulfills users' needs, the factors that need to be considered before a system is released on the market and the diversity of the international library contents on the Internet. Keywords: digital library, user interface, digital content, multilingual information retrieval, system evaluation. 1 IntroductionDigital technologies form the backbone of constructing tools that respond to the increasing demand for information retrieval all over the virtual world created by the Internet. The information is provided in almost all of its forms such as:
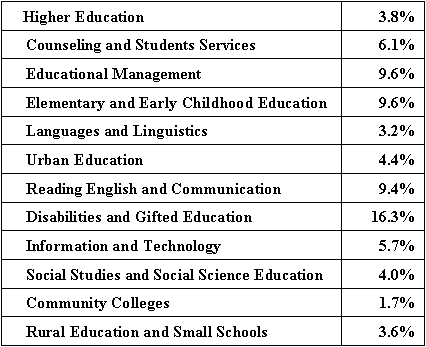
Machine translation systems, search engines, and multilingual information retrieval systems of different kinds, and eventually international digital libraries, seem to be the most popular sources of information that enable the users to surmount language boundaries. Designing an interface for a particular group of users is a complex process that is oriented towards demonstration of the system's potential capabilities [7]. Careful consideration of both system and user characteristics is the key to success for effective design. The International Standard ISO/IEC [11] defines the factors that should be considered while designing a digital library system. For the purposes of this study, some of these factors have been selected, including system operability, readability, suitability, and efficiency. Operability indicates the ease with which the system can be used. In other words, it is the extent to which the system is able to achieve its goal, or can be called user-friendly. Readability refers to the clarity of the digital content, whereas suitability is defined as the system's capacity to meet end-user needs by providing the information searched, especially the one that exists in a language other than the query language. Efficiency relates to the amount of information retrieved under certain stated conditions, for instance, retrieved within a set period of time. The diversity of users of digital services is represented in Figure 1 based on survey results that show the areas of user interests [12]. The Educational Resources Information Center (ERIC) is the world's largest educational digital database.
This figure indicates that the user population can be grouped into practitioners, teachers, students, researchers, counselors, policymakers, parents and administrators. According to this survey, the materials searched are mainly research reports, project descriptions, position papers, evaluative reports, literature, teaching guides, books and conference papers. The brief presentation of the system characteristics, user groups and the areas of their interests in digital collections is the key point to take into consideration when designing the model for an interface. In the work described in this paper, the focus has been shifted towards English and French digital libraries, since, according to the Global Search survey, the English and French languages are two of the ten most popular languages used on the Internet. This language pair phenomenon relies on the resemblance that is transformed at the translation stage, if required by the system. In addition, most of the people in England and France seldom speak the language of the other nation. One piece of evidence that a system interface has been successfully designed is that the interface even attracts the attention of laypersons. Such an approach leads to popularization of digital content like, e.g., cultural heritage, literature, history, nature, medicine, art, science or entertainment. Although cross-lingual techniques can allow the user to access digital documents in a language different than the query language, in fact, such tools are hardly ever available to users. The design of a multilingual interface model is intended to provide information for system producers about what factors should be taken into account and why it is important. 1.1 User Characteristics and System TechnologyThe idea of constructing a model design for a digital library interface is based on Moustafa A. Youssef's work on Cross-language Information Retrieval [1], but his idea was extended and adapted to the requirements of international digital systems. A design is considered universally usable when it addresses typical features relating to users, such as computer literacy, physical disability, competence in a foreign language, age group [8], or proficiency in the field of digital library content. Technical system characteristics should also be considered, as they determine, to some extent, the translation quality that can make a library collection more accessible to users. Thus, the proposed model design of a digital library interface should include:
1.2 Information Retrieval from Digital LibrariesFor browsing digital collections, many technical approaches have been adopted. Their selection is dependent upon the purpose being served by a particular digital system. The matching techniques refer generally to the multilingual digital systems [10]. The most common seems to be free-text searching, which relies on retrieving every document that contains one word or phrase used in the query, depending on wildcard symbols or Boolean operators. AltaVista employs this technique. Another approach is automatic query enrichment before and after translation in which the system has a built-in wordlist or glossary and the parser completes the queries as soon as it recognizes a possible collocation or expression. Matching for out-of-vocabulary words is the technique in which the words are marked up with their parts of speech (e.g., noun, verb, adverb, etc.) according to the algorithm presented below. If the word is known, it is marked up with the tag (as a noun, for example). Otherwise the system makes a guess by tagging it with the part of speech assumed to be correct.
Interactive browsing performed on a document-by-document basis is very time-consuming, but it is common in the case of a specific search, e.g., an interactive Internet-based search for interstellar dust in the Stardust aero gel collector, or when professional translation of the documents is of special importance. An InQuery text retrieval system from the University of Massachusetts is an example of this technique. Automated or machine-assisted translation of texts is the most popular technique although, despite the diversity of methods utilized by the systems, the translation quality resulting from machine translation remains incomparably worse than the quality resulting from human translation [13]. Interactive selection of a promising document from a list is another common technique utilized by all the digital systems. It does not require a good language command from a user and is oriented towards semantics of metadata. 1.3 Search EnginesSearch engines with built-in machine translation systems are the tools responsible for the translation quality of multilingual libraries, which results in the number of hits, as well as the digital system capabilities as a whole. The quality of search engines depends upon the databases utilized, their contents, and searching techniques. In general, databases, the information sources utilized by the particular digital library system, include Web pages, news, maps, yellow pages, e-mail addresses or subject guides. In some cases (e.g., a Metasearch engine called Inference Find), instead of building in its own database, a system searches the databases of other engines. Search engine contents constitute the Web index with thousands of links to Internet resources. The only option is to choose the time of waiting for the results retrieved from other databases. In general, every search engine uses at least one of the following four strategies:
Apart from its multilingual feature, FreeFind, which is both a search engine and a library of search engine knowledge available on-line, indexes over 100,000 Web pages, utilizes both simple and advanced Boolean search strategies, offers three types of phrase matching, can be re-indexed according to a schedule or manually, and includes a variety of file formats like pdf, doc, PowerPoint, Open document and Open Office. FreeFind also generates three styles of user choice, database style searching and password authentication. (Interested readers can find more information at the FreeFind Library web site at [5].) Subject Directory contains a subject guide to resources created by librarians. Apart from a simple search by title, description, or subject, it offers advanced search with Boolean operators, optional stemming, or categorizing the matching results to the databases selected from the list. The results can be put in alphabetical order. The aim of the Subject Directory system designer is primarily to serve California digital librarians [14].1.4 OPAC – Online Public Access CatalogDigital library systems hold information about the library's materials in computerized on-line public access catalogues (OPACs). Apart from CDs or search services, OPACs are simply digital devices used by libraries. The advantage for the users of an OPAC is that it can be accessed both within the library and from home. The idea of the OPAC was introduced in the 1980s with the intention of building integrated multi-terminal DL systems, but nowadays the systems are basically used for browsing the library's catalog. The bibliographic data are open to the public. Some OPAC systems present book covers, selected book chapters, or video clips. The interface graphics offers pulldown menus that allow the user to restrict the query to the documents searched in order to make it more precise. In view of developing new trends for designing OPACs, researchers in the field drew up a set of draft of recommendations [15]. Here are some of them:
In Section 2 of this paper, Gallica is presented as an example of an OPAC system. 1.5 MetadataIn a digital library, metadata constitutes a set of attributes for describing electronic resources, like collections of books, journals, newspapers, or other digital objects. Metadata makes possible identifying resources, locating information in a digital catalog, archiving and preserving a digital collection, or aggregating objects, and is specified in a metadata scheme, e.g., AACR2 [16]. There are different kinds of metadata, including:
Metadata schemes are structured according to the type of digital object with the attributes identified as semantics and their numbers as the content. Eventually, the scheme defines the syntax rules for coding the attributes. The metadata languages used are SGML (Standard Generalised Mark-up Language), XML (Extensible Mark-up Language), or HTML (Hypertext Mark-up Language). SGML, one of the metalanguages that extended from GML to HTML, provides a variety of mark-up syntaxes for attributes. Its uniform type identifier is just XML. A set of rules is specified in its DTD – Document Type Definition.
The metadata in Figure 3 above is in XML format. It describes parts of the annual presidential reports of Radcliffe College for the period of 1912-1914. This is a citation-level metadata record, which is a root node in a tree of METS files. 2. The Digital Library Interface Conformity with the ModelIn this section, some digital libraries have been selected in order to analyze their interfaces in light of their conformity with the model presented. The selection criteria include languages (English and French), content, unprotected accessibility to the digital collection, range of readership (also popularity), modes displayed (if any), search strategy and kinds of services. All the features are assumed to be included in search interface design. Due to the fact that currently there are not very many multilingual libraries on the Internet that present a diversity of usability criteria, for the purposes of the evaluation the following three digital libraries have been analyzed: Gallica [2], IntraText [3], and Digital Librarian [4]. This selection provides the opportunity to indicate all the features proposed in the model. Each of the libraries is of a different nature, so this gives us a view of how the model works in practice as well as what could be improved upon in the digital system being evaluated. 2.1 Gallica – France in AmericaThis bilingual library launched within Bibliotheque National de France (BnF) has an extensive collection of seventy-six thousand digitized texts of rare books, manuscripts, prints, photographs, and maps, and eighty thousand images documenting the French presence in America dated from the 16th to the 19th century. The documents trace the history of the Seven Years' War, the American Revolution and the U.S. cession of Louisiana. According to a survey, there are more than a million searches of Gallica per month. The search engine interface is organized into Title Word, Author, Subject, Key Words and Document Type. Each of the document types has its own symbol. The document types include: texts, monographs in image mode, periodicals in image mode, still images, sound documents and manuscripts. The searching criteria can be combined.
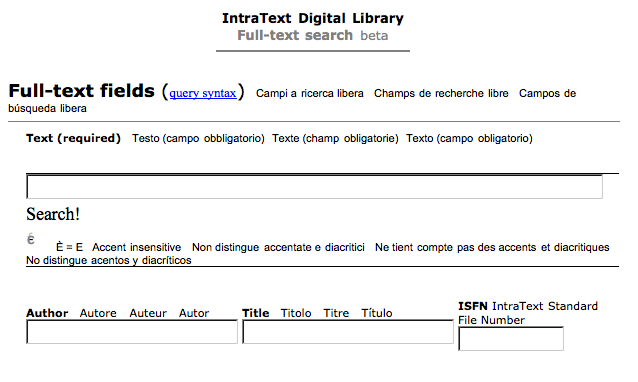
Figure 4 shows the interface design and the results of mining the French Web page library collection for English documents. The search engine retrieves five documents and displays their titles and types. The preface presents the information extracted from the documents with their reference number, and the last part of the figure relates to the second line indexed by number 20. This is a fragment of a scanned historical monograph in image format. Apart from details concerning the library, the research projects are presented to indicate the improvements planned such as indexing customised by the target user, integration of images with other relevant materials, or extension of search functions to all map materials. The subject area of the collection includes: dictionaries, bibliographies, history, philosophy, religion, geography, law, economics, sociology, education, political science, science technology, architecture and language linguistics. Gallica also facilitates search by the visually handicapped so they can access the library's collections. 2.2 IntraText Digital LibraryThe IntraText Digital Library was launched in 1999 by Eulogos, an Italian provider of on-line Internet services and a designer of relational systems interfaces. IntraText's collections contain books, periodicals, scientific works and religious texts in thirty-six languages, including French and English. There are even some items of Polish literature. The texts are in XML format and all the items are available on CD as well. Researchers are allowed to publish their works free of charge. The IntraText interface supports advanced, full-text search with query syntax, both single terms and phrases.
The IntraText search option supports fuzzy, proximity and wildcard searches. The user can select a number of results on a page, a synthesis that, apart from the hits, offers links to their matching pages, and analysis that adds the extras to the pages. The system has been tested on eight of the most popular browsers including Opera, Netscape and Lynx. The recommended lowest screen resolution is 800x600. Although the system is compatible with tools for the blind and other disabled people, no special options have been provided in its interface. The text collections are in hypertext. The InterText library collections address Catholics, Buddhists and other religious groups, Latin and classical literature of many countries enthusiasts, linguists, NLP researchers, doctors and philosophers. The interface is provided in six languages and around million library pages are accessed every month. In 2002 the total number of books available reached three thousand. The on-line catalogue is classified into three categories according to authors, titles and languages, all of which are put in alphabetical order. 2.3 Digital LibrarianDigital Librarian is not a library in the true sense of the word, that is, neither does it have digital devices, like CDs, nor its own search box, nor library-like organized content like a collection policy, cataloging, preservation, or at least its own digital content such as databases, digital media or files [6]. Digital Librarian is simply the Web page of an American librarian, Margaret Anderson, with around a hundred links classified into subjects, each of which connects the user to the home pages of books, newspapers, etc. The simple search mode is incorporated by Amazon.com, an on-line bookstore.
The Digital Librarian interface supports searching for books by author, title, subject, ISBN, and publisher. The user may choose the format desired from the following: hardcover, paperback, e-books, documents, audio downloads, calendars, or books on CDs or cassettes. Other information provided by the user includes the reader's age, the language of the book and the way in which the search results should be sorted, e.g., by date, price, best-selling, customer reviews, or alphabetically. There is a special Search Magazine Subscription page in which the items can be selected by format like magazines, newsletters or newspapers and searched by title, subject, publisher or ISSN. 3 Evaluation of the Digital LibrariesThis section attempts to evaluate the libraries presented above by comparing them. The goal is to highlight the features that seem the most essential for designing the model of interface. For the purpose of this study, the following criteria, which were described earlier, are considered: operability, readability, suitability and efficiency. Under these criteria, both the user and the system characteristics have been classified accordingly:
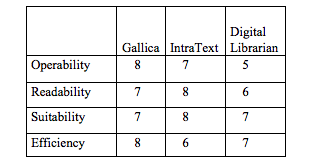
To ensure uniformity, the libraries are compared by rating them on a nine-point scale proposed by Van Slype in his Critical Report [9].
Assuming equal importance for the criteria, the average score for the digital libraries would be: Gallica 7.5, IntraText 7.25 and Digital Librarian 6.25. Although such an approach seems rather subjective, it provides some information about the interface design. The measure of usability in general was the time it took to access the French and English documents of a different genre. All of the libraries analyzed have been tested on different platforms, and the weakest point of all the interfaces is a lack of options for the disabled user. Gallica proved to be the best at searching for books, manuscripts or newspapers, but the user is expected to have some computer literacy and language competence. IntraText, with its clear interface design and suitability for all the user groups, is oriented rather towards religious documents. Digital Librarian, when compared with the libraries presented, supports an easy to use search box that allows the user to find items quickly, but the AmazonOnlineReader offers only the front cover of the book. Also, the help offered is only a customer service option. The analysis of the above three interfaces is an attempt to indicate improvements needed in order to make the interfaces better for users of any age, profession or education level to navigate through the systems in a way that is both easy and fast, as well as to showcase all the capabilities offered. 4 ConclusionThe increasing usage of digital libraries poses a new challenge for interface development. Designing an interface involves many professionals such as software engineers, graphic designers, human factor specialists, and technical writers, and also very often statistical consultants, all of whom cooperate to meet the project goals. The model presented in this paper is not only consistent with target user needs, but it is also content-dependent and complete. Although the model refers to digital libraries, it can be extended to other cross-language information systems on the Web. However, the increased development of technology shows that there are no standard names for the information retrieval techniques. The diversity of digital library contents and their interface designs show that in future studies more examples analyzed will result in improving the model with some additional features. References1. Moustafa A.Youssef: Cross Language Information Retrieval, Department of Computer Science, University of Maryland, Universal Usability in Practice, 2001. 2. Digital Library Gallica, <http://gallica.bnf.fr/>. 3. Digital Library IntraText, <http://www.intratext.com>. 4. Digital Librarian <http://www.digital-librarian.com/medieval.html>. 5. FreeFind Library <http://www.freefind.com>. 6. Douglas W. Oard: Throwing the Book in Digital Library, Collage of Library and Information Services, Cross-Language Text Retrieval Research in the USA, 1997. 7. Mastidoro N.: The Intratext Project, The University of Edinburgh, 2002. 8. Druin A.: Designing a Digital Library for Young Children, Association for Computing Machinery, Proceedings of the ACM Conference, Virginia, 2001. 9. Van Slype G.: Critical Methods for Evaluating the Quality for Scientific Information and Information Management, Report BR-19141, Bureau, Marce Van Dijk, 1997. 10. Douglas W. Oard: Serving Users in Many Languages, D-Lib Magazine, 1997 <http://www.dlib.org/dlib/december97/oard/12oard.html>. 11. ISO/IEC. International Standard ISO/IEC 14598-2. Information technology - Software product evaluation - Part 1: General overview. International Organization for Standardization / International Electrotechnical Commission. Geneva, 1999. 12. Gene V. Glass, Education Policy Analysis Archives, vol.8, no 44, 2000. 13. Daging He :Comparing User-Assisted and Automatic Query Translation, CLEF 2002 Workshop Rome, Italy. 14. Internet Search Tool Details <http://sunsite.berkeley.edu/Help/searchdetails.html>, Berkeley Digital library SunSITE, 2000. 15. IFLA Task Force on Guidelines for OPAC Displays, Draft for Worldwide Review, 2003. 16. National Information Standards Organization: Understanding Metadata, NISO Press, 2003.© Copyright 2007 Jolanta Mizera-Pietraszko Top | Contents |