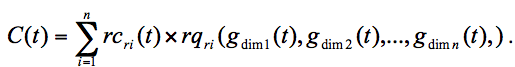|
|
|
TCDL Bulletin A Scalability Survey in IR and DLAmélie Imafouo AbstractNowadays, many factors support a growing production of information. Domains like Information Retrieval or Digital Libraries that deal with digital information are highly concerned by this growth that has an impact on information systems performances. In this study, we analyze the way these two research fields face the problem of scalability. IntroductionDigital Libraries (DL) are concerned with the creation and management of information resources, the movement of information across global networks and the effective use of this information by a wide range of users. One of the services offered by a DL is to retrieve "relevant" digital objects and return them to the user. The DLs then use the same mechanism as Information Retrieval Systems (IRS) to return relevant digital objects, as the Information Retrieval (IR) process consists in providing, in response to a user request, documents that as well as possible meet his information need. To provide their services over a long time, digital libraries have to be scalable to support for future growth in different dimensions, for example in the number of users and/or in the number of stored documents. The assessment of scalability is therefore an important aspect of the assessment of digital libraries [1]. Scalability is an issue that has not yet been handled by many retrieval research works although it is recurring in the different steps of an IR process (collection building, indexing, querying, evaluation). Our work is currently on setting up large retrieval spaces: we propose a methodology for sampling large retrieval spaces and studying the way collection size acts on retrieval models behavior. We are also interested in the evaluation phase of a retrieval process, and we design measures to analyze the retrieval tools ability to rank documents according to their relevance levels (for instance highly relevant firstly, then fairly relevant documents and finally marginally relevant ones), as previous work characterized relevance as a complex cognitive problem that should be represented over a multi-levels scale. 2 The information growth2.1 The information growthNowadays, many factors support a growing production of information. The quantity of information corresponding to static web pages or to pages calculated without parameters on the web is currently estimated to 170 teraoctects. A regular increase of 30% was noted between 1999 and 2002 [2]. A study estimates the quantity of information produced in 2002 to 5 exaoctects, 92% stored numerically. One can expect a continuous growth of this volume of information since the number of users is unceasingly increasing and their activities are intensifying. Many reasons can explain this increase: access to large disk spaces speed up the information production, documents digitalization techniques have become more powerful and the need to quickly and efficiently exchange information is higher. This continuous growth of information is also obvious in DL domain as we describe it below. The problem of structuring/cataloguing and accessing this mass of information easily comes under the fields like digital libraries and information retrieval, but currently few works of both domains (IR and DL) have taken into account the size effect in their approaches. 2.2 DL:definition, growth, attributesSeveral terms have been used interchangeably at various times to try to encapsulate the concept of a library full of digitized data that represents information and knowledge. These terms include the electronic library, the virtual library, and the library without walls, as well as the more recent digital library. The following working definition has been proposed and seems to make unanimity among partners involved in the field: Digital libraries are organizations that provide the resources, including the specialized staff, to select, structure, offer intellectual access to, interpret, distribute, preserve the integrity of, and ensure the persistence over time of collections of digital works so that they are readily and economically available for use by a defined community or set of communities. Another factor that can bring confusion in the definition is that digital libraries are at the focal point of many different areas of research, and what constitutes a digital library differs depending upon the research community that is describing it [3]. For example:
In little over a decade (since the 1990s) thousands of digital libraries in a variety of forms have been built and are functioning operationally, with more to come. Libweb, (a directory of libraries on the web maintained at University of California, Berkeley), currently lists over 7.100 links to web sites from libraries in over 115 countries. Hundreds of research projects were devoted to great many aspects of digital libraries in great many countries, and more are reported each year [4]. There are quite a large number of activities being undertaken in European countries with respect to digital libraries – some on a European level, some on a national level, and others on a much more local level. We can cite The Telematics for Libraries program of the European Commission, Candle (Controlled Access to Network Digital Libraries in Europe), Decomate II (Delivery of Copyright Materials in Electronic Form) as projects funded by the European Commission and many others. Raitt [5] listed National Digital Library Initiatives for more than 10 European countries. 3 Taking the information growth into account3.1 Problems dealing with scalabilityScalability (in IR) faces two main problems: on the one hand the mismatch between the hardware configurations and the current needs for information storage and processing, and in addition, the complexity of IR algorithms. Concerning efficiency, the average time to index collections increases in a very significant way according to their size [6]. Solutions suggested for this scalability limit are based on physical information compression but their impact on the retrieval performance remains insignificant [7]. The increase in the information granularity by using aggregate concepts to represent information (rather than low level information units like the terms or the n-grams) is a track that will allow the reduction of the representation space. The average time for processing requests also scales badly. Techniques that aim to reduce this time require better knowledge of the user information need, which makes it possible to identify sub-collections (i.e., to reduce the size) that would be enough to carry out search and meet the user's need. The question then is how to segment the collection (collection segmentation based on questions answered by users, segmentation based on a users profile [8]). The goal of these various techniques is to quickly prune the information considered to be useless for processing requests. Other works rely on additional metadata related to the user information need and/or to the documents, thus allowing a better classification/segmentation of documents [6]. Concerning effectiveness, the recall measure (the proportion of relevant documents that are retrieved) encounters some limits due to the fact that there is increasingly more incompleteness in relevance judgments when the collection increases (IR experiments are usually based on static collections that are composed of a set of documents, a set of information needs or topics, and a set of relevance judgments on those documents using the topics). 3.2 Previous work in DL field concerning scalabilityThe work of Witten et al. [9], which concerns both the IR domain and the DL domain, is about creating publicly available DLs (collecting, selecting and formatting the material, cataloguing this material with bibliographic information in a usable format and providing a easy-to-use interface for retrieving digital objects). One way to do that is to arrange for authors to contribute information to the library, so that a traditional author/title/keyword catalogue can be built through which readers access the collection. The second approach, that is to gather material from public repositories without any active participation by authors is the one pursued by Witten et al. [9]. This approach allows creating a vastly larger collection, but requires a new mechanism for searching the library because conventional bibliographic information is not available. The key innovation of their project is that it dispenses with the traditional library catalogue. Indeed, if information providers must supply such information, the scope of the collection is thereby restricted. The alternative, cataloguing by library staff, means that the collection is limited by human resources. It was resolved by the authors that, although the collection would be formed entirely from publicly-available repositories of text, the system should not require any effort on the part of participating repositories, as there should be no need for the information providers to be aware of their inclusion in the index. Thus, no special software, archive organizations, or file formats are required of the providers. The only information used for cataloguing is derived from the documents themselves [9]. This is an approach that takes into account the scalability of DLs, by limiting the extents to which human resources/information providers can act on the DL growth. These authors also noticed that all sizes involved in such a library increase linearly with the volume of text and that the retrieval time was virtually independent of database size. Witten et al. [9] also study the possibilities for culling the collection when that becomes necessary, as an all-inclusive information collection policy is basically unscalable. One of the possibilities that they suggested is to monitor participating users access, and note the digital objects (in this case the repositories) that receive the least use. This regulates the growth of the collection by the size, diversity, and level of activity of the user population rather than by the growth of the bibliographic universe. Another possibility is to use the characteristics of the documents themselves to determine what to cull from the collection. For example, citation studies could identify documents that do not appear to contribute to the literature. An interesting work from Mönch [1] identified and outlined some factors for scalability of a digital library: the predictable or analyzable behavior of a digital library (the dimensions of growth, the resource requirements of the digital library), changes in the environment of the digital library (the estimated costs of resources, and the assumed growth rates of the growths dimensions). But firstly, a necessary precondition for scalability is the scalability of the technological infrastructure on which the digital library is built. They described their factors for scalability as follows.
With the given definitions, the overall costs per time unit c(t) of a digital library at a given time t evaluate to:
where Resources are represented by a set r1, r2,..., rn; Resource requirements are represented by a set of functions rqr1, rqr2, ..., rqrn, where rqri maps a vector of all scaling variables to the required amount of resource ri; Resource cost are given by a set of functions rcr1, rcr2, ..., rcrn, where rcri maps a time value to the assumed cost per time unit of resource ri at the given time, and finally the growth rates are given as a set of functions gdim1, gdim2, ..., gdimm, where gdimi maps a time value to the assumed value of the scaling variable dimi at a given time. The cost functions with some empirical data, for example for a yearly increase in the number of documents of 25 percent, could be modeled by the function g docs (t) = 1.25 t/12 x docs0, where t is months from now, and docs0 is the current number of documents. The scalability of the digital library depends on the costs per time unit, the operator of the digital library can provide. These costs are denoted by the function tc that maps a time value to costs per time unit. The digital library in question is scalable, if the condition c(t)<= tc(t) holds for all t [1]. This cost function has been used to study the scalability of two infrastructures for digital libraries (Indigo and a basic infrastructure of the World Wide Web). Both infrastructures support the scalability of the number of documents and the number of users. In contrast to the World Wide Web, Indigo has been designed to support the scalability of document types and the scalability of the supported services, and to allow for cheap introduction of new document methods and transparently integration of new services. This scalability function of cost proposed for DLs can be interesting to adapt in the case of IRS. 3.3 Metadata in IR and in DLMetadata is a central issue in the development of digital libraries; it is also a way proposed by some IR works to ease the scalability of retrieval. A number of schemes have emerged, the most prominent of which is the Dublin Core, an effort to try and determine the "core" elements needed to describe materials. Some IR works proposed approaches for easing IR scalability by pruning useless information when processing the request. These approaches require additional metadata related to user information needs and/or to documents to allow a better classification of documents. These metadata can give information about the nature of documents or the future use of documents. In the one hand, these metadata permit a better knowledge of the user need and an easier personalization of retrieval; in addition they allow a segmentation of the collection of documents in sub-collections. The lack of common metadata standards – ideally, defined for use in some specified context, is a barrier to information access and use in a digital library or in a collection of documents for an IRS, or in a coordinated digital library scheme. 4 Our work about scalability4.1 Sampling collectionsSome works provide techniques to sample large retrieval spaces into smaller sub-sets to ease the studies. Gurrin et al. [10] are interested in replicating the features of Web hyperlinks structure on a collection of reduced size. This relates to collection sampling: determine some properties of a large collection, build a collection of reduced size that has the same properties and perform studies on the reduced collection (which should be easier than on the whole collection) and generalize the results obtained on this reduced collection for the whole collection. Hawking et al. [11] studied the impact of the collection (size) on the attribution of a score to a document. They carried out experiments by building three types of samples of the collection:
A part of our work [12] provides a general experimental methodology to study how the retrieval models are dependant on collection size. This methodology is based on the construction of a collection on which a given characteristic C, that acts on some IRS properties {Pi}, is the same whatever the portion of the collection is selected. This new collection called uniform can be split into sub-collections of growing sizes on which the given properties will be studied. We applied this general methodology in the case of IR evaluation with characteristic C being generality (proportion of relevant documents in the collection) and {Pi} the standard IR measures. 4.2 Collection size and IRS effectivenessTwo measures generally help to carry out classic retrieval tools evaluation: precision is the proportion of retrieved documents that are relevant; recall is the proportion of relevant documents that are retrieved. Hitherto, few researchers tackled the collection size impact on effectiveness. The relevance evaluation of retrieval results depended neither on collection size nor on corpus diversity, and this can generate biases when comparing different IRS performance. This is one of the main goal of the TeraByte task introduced at TREC in 2004. Some researchers use classic IR measures on collections of increasing size to analyze retrieval tools effectiveness and scalability. While collections sizes are growing, the main diffculty for an IRS is to retrieve (very) relevant documents at very top position in its results list. This particular ability is called high precision: it expresses the rate of relevant documents between the first documents retrieved. Hawking et al. [11] analyzed high precision evolution when sample size increases and noticed a decrease of high precision when sample size decreases. This decrease is due to two main factors: one major explanation is simply the reduction in the number of relevant documents; the second factor is the ability of the (Query, IRS) combination to rank relevant documents ahead irrelevant ones, as P@n decreases with sample size even if there is no limitation due to the lack of relevant documents in the sample. Current evaluation measures are not robust enough for substantially incomplete relevance judgments. Voorhees et al. [13] introduced a new measure (bpref for binary preference) that is based on the relative positions of relevant documents and documents judged irrelevant. This measure is both highly correlated with existing measures when complete judgments are available and more robust with incomplete judgment sets. This finding suggested that substantially larger test collections built using current "pooling" practices should be viable laboratory tools, despite the fact that the relevance information will be incomplete and imperfect. We analyze the behavior of classic IR measures on a set of collections built using our methodology described earlier in section 4.1. To return a results list for a given query, any retrieval tool computes a score for documents in its retrieval space and ranks these documents in decreasing order of their scores. Our experiments showed that, for an IR model, the role of the collection in the attribution of document scores affects the way this model scales (regarding classic IR measures). The IR models for which a document score depends only on the query terms and on the document seem to scale better than those for which the document scores depend on some collection characteristics. Our work also generalizes the results obtained by Hawking et al.[11] on high precision to five IR models (vector, okapi, and three models based on proximity between terms). 4.3 Evaluation metrics for scalabilityIn classic retrieval evaluation, relevance is consider to be a binary notion. However, Mizzaro [14] characterized the various types of relevance. Some other research works provide frameworks for classifying relevance. These works suggest that relevance is a complex cognitive problem and that there are many relevances. In modern large environments, in the user's point of view, it is desirable to have IRS that retrieve documents according to their relevance level; for instance, highly relevant documents first, fairly relevant documents second, and finally, marginally relevant documents. IR evaluation methods should then credit IRS for their ability to retrieve highly relevant documents at the top of their results list. To reach this goal, it becomes necessary for IR evaluation to take into account various relevance levels of a document for a given query. Relevance levels have been studied in some previous IR research, and multi-point scale for relevance assessments have been proposed. The TREC Web Track collection employed a three-point scale [15]. For a given document and a given request, Kekäläinen et al. [16] defined a four-point scale for relevance level and proposed measures based on multi-graded relevance assessments. We are designing measures to analyze the behavior of IR models when they are used on increasingly large retrieval spaces. These measures assume multiple relevance levels for documents. For two collections (of different size) and for a search engine, we compare relevance levels of first documents retrieved for each collection. This helps to determine if the search engine performs better, worse or remain stable when collection size increases. We also compare relevance levels of first documents retrieved to a so-called ideal results list. This measure provides information about the way the search engine ranks documents according to their relevance levels when collection size increases. 5 ConclusionCurrent growth in the amount of information and the growing number of digital information users are challenges for all fields dealing with information, and especially for the IR and the DL fields. We investigated this growth and analyzed its infuence on both the IR domain and the DL domain. Similar problems arise for both fields; nevertheless, the IR domain has the advantage that evaluation campaigns (e.g., TREC) provide environments for repeatable experiments and studies about different issues, among which is the scalability impact on system effectiveness (Terabyte Track of TREC 2004). Nowadays, evaluation is not an activity in which digital libraries are widely engaged. Relevance has not yet become a basic evaluation criterion, and there are no other more or less standardized evaluation criteria [4]. Much work remains to be done to realize effective measures and metrics in viable digital library test suites and to develop valid and understandable comparisons useful to the digital library community [17], although experience from prior evaluation projects (e.g., TREC in IR) clearly indicates the high costs encountered for collection development in controlled experiments. About the authorAmèlie Imafouo (http://www.emse.fr/~imafouo) is a Ph.D. student at Ecole Nationale Supèrieure des Mines of Saint-Etienne in France. She works with Dr. Michel Beigbeder (http://www.emse.fr/~mbeig) on the scalability impact on advanced Information Retrieval Models. Her research team is part of the Department of Industrial Engineering and Computer Science, and the team's main interests are creation, organisation, classification, structured documents and Information Retrieval. References[1] Mönch, C., On the assessment of scalability of digital libraries. In Fourth DELOS Workshop. Evaluation of Digital Libraries: Testbeds, Measurements, and Metrics. (2002). [2] Lyman, P., Varian, H.R., Swearingen, K., Charles, P., Good,N., Jordan, L.L., Pal, J., How much information 2003?. http://www.sims.berkeley.edu/research/projects/how-much-info-2003/ (2003). [3] Cleveland, G., Digital libraries: definitions, issues and challenges. http://www.ifla.org/VI/5/op/udtop8/udtop8.htm (1998). [4] Saracevic, T., Evaluation of digital libraries: An overview. (2004). [5] Raitt, D., Digital libraries initiatives across europe. In Computers in libraries, 20 (2000) 26-35. [6] Chevallet, J.P., Martinez, J., Boughanem, M., Lechani-Tamine, L., Calabretto, S., Rapport final de l'AS-91 du RTP-9 'passage à l'échelle dans la taille des corpus' (2004). [7] Witten, I.H., Moffat, A., Bell, T.C. In Managing Gigabytes - Compressing and indexing documents and images. Second ed., Morgan Kaufman Publishers (1999) 45-468. http://www.cs.mu.oz.au/mg/. [8] Newby, G.B. The science of large scale information retrieval. Internet archives (2000). [9] Witten, I., Nevill-Manning, C., Cunningham, S.J., Digital libraries based on full text retrieval. In Proceedings of WebNet 96, San Francisco (1996). [10] Gurrin, C., Smeaton, A., Replicating web structure in small-scale test collections. Information retrieval, 7 (2004) 239-263. [11] Hawking, D., Robertson, S., On collection size and retrieval effectiveness. Information retrieval 6 (2003) 99-105. [12] Imafouo, A., Beigbeder, M., Scalability influence on retrieval models : An experimental methodology. In 27th European Conference on Information Retrieval. (2005). [13] Voorhees, E., Buckley, C., Retrieval evaluation with incomplete information. In Proceedings of the 27th annual international conference on Research and development in information retrieval. (2004) 25-32. [14] Mizzaro, S., How many relevances in information retrieval? Interacting with Computers, 10 (1998) 303-320. [15] Voorhees, E.M., Evaluation by highly relevant documents. In Proceedings of the 24th annual international ACM SIGIR conference on Research and development in information retrieval. (2001) 74-82. [16] Kekäläinen, J., Järvelin, K., Using graded relevance assessments in IR evaluation. Journal of the American Society for Information Science and Technology, 53 (2002) 1120 - 1129. [17] Larsen, R.L., The dlib test suite and metrics working group: Harvesting the experience from the digital library initiative. In Fourth DELOS Workshop: Evaluation of Digital Libraries, Testbeds, Measurements, and Metrics. (2002). [18] Voorhees, E., Harman, D., Overview of the sixth text retrieval conference (trec-6). In NIST Special Publication 500-420 - The Sixth text retrieval Conference. (1997). [19] Zobel, J., How reliable are the results of large scale information retrieval experiments. In Proceedings of the 21th ACM SIGIR conference on Research and development in information retrieval. (1998) 307-314. © Copyright 2006 Amélie Imafouo Top | Contents |