|
|
|
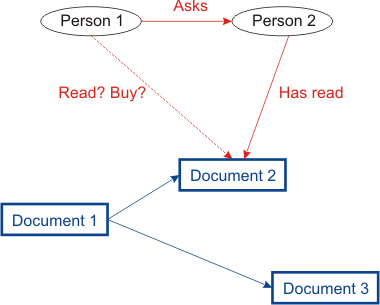
TCDL Bulletin Trust-Based Recommendations for PublicationsA Multi-Layer Network ApproachClaudia Hess AbstractCurrent recommender systems using network data focus on a single network, either a trust or a document reference network. However, in a number of applications, several types of networks need to be taken into account. This paper describes an architecture for a recommender system for publications that integrates information from different networks. Relationships in the trust network are modeled in a semantically rich way to reflect trust relationships from real life in a concise way. IntroductionTrust-based recommender systems have attracted much attention in recent years in research as well as in commercial applications. Well-known examples are the Epinions1 platform for consumer reviews and ebay's reputation system2. They use information about trust between users. Some systems infer recommendations from the network, linking users by trust relationships (e.g., [Guha, 2003], [Kinateder and Rothermel, 2003], [Montaner et al., 2002]). Other recommendation systems evaluate citations between documents (e.g., [Page et al., 1998]). Current recommender systems analyze only data from one type of network, either a trust or document network. Trust relationships cannot automatically be extracted from the document network. Neither is it possible to infer citations from the trust network. This paper proposes a layered architecture that integrates different network data, collected independently from each other but analyzed jointly. To provide a realistic modeling of trust, semantically rich trust statements are introduced. Semantic Web technologies like ontological modeling provide the basis for formalizing complex, multi-criterial trust relationships. The rest of the paper is structured in the following: section 2 describes one of the use cases motivating the presented research proposal. Sections 3 and 4 present the central research areas. Both sections discuss related work and highlight areas for research addressed in the dissertation project. The former describes the multi-layer architecture whereas the later section introduces complex trust statements. Open research issues of the dissertation project are summarized in the last section of the paper. Recommendations for PublicationsAn important use case in this context is that scientists often have to decide whether an article is worth reading or whether a pay-per-view article is worth buying. The article's abstract is often insufficient from which to make a decision. In research fields such as computing, abstracts contain information about the problem solved but often do not provide algorithmical details. Users could also ask colleagues who are experts in the research domain of the article whether they have already read the article and can recommend it. To find the appropriate persons to ask, it would be necessary to know which articles they have read and, above all, that the appropriate person is available. This work claims that a trust management system integrating information from different networks can support the user in making the decision by directly offering a trustworthy person's opinion or review of the article. Figure 1 shows a typical request and a way of answering it by exploiting the trust network.
Documents like scientific papers are linked via citations. Wouldn't it be sufficient to recommend the articles that are prominent in the scientific community? A prominent paper is, for instance, a paper that is read or cited very often, whereas a paper with low prominence is one that is very unlikely to be accessed. Several measures for the prominence of a paper exist in bibliometry, scientometrics, social network analysis, network physics and information retrieval. Following [Malsch and Schlieder, 2002], we refer to such measures as measures of social visibility. A measure for visibility considers several criteria. An important one is the visibility of the publications citing the paper, i.e., a paper is more visible when important papers are citing it more frequently. Another criterion is the author's visibility derived, for example, from his or her reputation in the scientific community. Despite the various considered criteria, high visibility is often insufficient for recommendations. It would, for instance, be false to recommend a highly visible paper if it was proven that the paper has been manipulated. Such a paper might be frequently cited until the manipulation was detected. An example is the case of scientific misconduct published by the German science foundation (Deutsche Forschungsgemeinschaft) in 20043. Two publications4 were based on fabricated and manipulated information. Hence, they should no longer be cited. However, a visibility-based system would still recommend them. One of the articles, for instance, has a rather high visibility, because it was cited at least 71 times between 2000 and 2002 according to the NASA Astrophysics Database System5 from which the article can be downloaded. To rely only on the publisher's reputation is insufficient. The fraud was neither detected during the peer-review process nor is there any information about the fraud before one downloads the paper. Multi-Layer Networks for High Quality RecommendationsIntegrating different types of information in a multi-layer network would permit recommendations of a high quality. Visibility as single criterion is insufficient to provide high quality recommendations. However, merely trust-based recommender systems also have their disadvantages. Users will obtain recommendations only about a limited number of papers, namely those that have been read by their colleagues. Recommendations thus risk being restricted to publications within one's own scientific community. Coupling several networks, at least a document and a trust network, permits combining the advantages of a trust-based recommender and measures of social visibility: reliability and personalization is guaranteed by using the trust data, and the coverage of recommendations is enlarged by considering the visibility of the documents. A Multi-Layer ArchitectureThis paper proposes a layered architecture with three networks as depicted in Fig. 2. The first layer consists of a trust network between persons. Persons can be both readers who are using the trust management system to obtain recommendations and authors of articles. The trust statements are associated with the edges between the persons. Trust can be propagated in the trust network in order to express that users to some extent trust other people, even if they do not know them, when the unknown people are trusted by other people the users trust. The second layer is the document network, which consists of the pay-per-view articles rated by the researchers and additional articles, e.g., all articles indexed by CiteSeer6. Persons are connected to documents either by being its author or by being a reader. Having read an article, the reader has an opinion about it. The opinion could be written down in the form of a review. The third layer is the organization network. Organizations and institutions are connected via cooperation relationships that often go along with trust relationships between the organizations. Persons are connected with organizations via membership, e.g., 'is professor at'. Layers are not arbitrarily connected but only with the preceding and the succeeding layer.
Research in recent years focused on the understanding of the different kinds of networks, the development of applications and algorithmical support. Interdependencies between networks and their integration have only recently been addressed. An approach to the integration of document and author networks has been proposed by [Börner et al., 2004]. Their focus is the simultaneous growth of coauthor and citation networks in time. Relationship types are co-authorship between authors, inception and reception of documents by authors, and references between documents. The growth process is driven by authors who write papers together with other, randomly chosen authors working on the same topic. Connecting Persons and Documents: Opinions or Explicit Reviews?A trust management system based on multiple layers could answer requests in two different ways. Firstly, the user could obtain the name and contact address of colleagues determined by the system as well-suited to answer the user's question. The user could then directly ask their colleagues for their opinions on the pay-per-view article. Secondly, the requester could directly obtain the reviews made by the persons computed as trustworthy for the request. Reviews are made by those users who already bought the pay-per-view article. A paper would be evaluated by its readers according to criteria similar to those used in the reviews for conferences or journals. When defining the criteria used in the reviews, it must be considered that the review should be easy to do in order to keep the additional time needed for the scientists to do the review as low as possible. The reviews could be presented separately or aggregated by the trust management system. The first case has the advantage that the time and effort required by the scientists are minimal. Users only assign trust values to their colleagues and indicate which articles they have read. In contrast, the second alternative requires that users provide explicit reviews about the articles. The advantage of the second approach is that users could obtain recommendations by persons who could not, or at least not easily, be contacted. For instance, a student would rarely dare to contact some well-known experts and ask them about their opinions only in order to decide whether to read or to buy an article. Thus, it depends on the structure of the community whether the better result would be a list of recommended persons to ask about their opinions or a set of reviews by trustworthy persons. Written reviews will be the favored if users frequently change. In a stable network in which users remain over a long time period, and in which users can directly contact each other, it would be sufficient to know whom to ask. Computing Recommendations in Multi-Layer NetworksIn order to automatically classify a faked article as 'strictly not recommended', as would be appropriate in the above example, there must be at least one distrust statement. The source of the distrust statement could either be some trusted scientist or some trustworthy organization. The target of the distrust statement could be, on the one hand, the manipulated paper and on the other hand, the author of the manipulated paper. To assign the distrust to the author is sensible under the assumption that someone who has cheated once will do so again or may have done it before without the cheating being detected. Thus, four different kinds of distrust statements are conceivable:
According to the concrete situation, source and target of the distrust relationship must be chosen, also considering the interdependencies between the different layers. Distrust in authors can be propagated to their papers. Bad reviews can influence the trust value, too. Despite of the interdependencies, the semantics and the effects on the recommendations differ between trust statement about the author or reviews of the article. Trust or distrust relationships between authors cannot be extracted from the reviews and citations and vice versa. Coauthors are also affected by the distrust. This would exclude all future and past papers of these authors from being recommended. Therefore scientists should be able to assign trust not only to their colleagues reviewing papers, i.e., trust in their reviewing capabilities, but also to the authors of the papers, i.e., their trust in the author's capability of writing 'good' papers. Trust StatementsThe trust statements between persons are a central aspect of the trust management system. Most applications use rather simple trust statements like the research project FilmTrust7 which statements are numerical values or the platform Epinions that distinguishes only trust and distrust. For the presented trust management system, such trust statements are too restricted. An approach to modeling differentiated trust statements is presented in the following, which on the one hand, integrates different extensions to the current way of representing trust and on the other hand, introduces complex trust concepts. Trust and DistrustTrust statement should not be restricted to trust relationships but include distrust. This would be necessary, for example, in order to express that a user distrusts an author who already manipulated publications. Until now, only few trust-based recommender systems deal with distrust values. Trust metrics for the propagation of trust between users become more difficult when integrating distrust. Most trust metrics like, for instance, [Golbeck et al., 2003], [Ziegler and Lausen, 2004], are limited to positive trust values. [Guha et al., 2004] discuss a number of research issues on distrust also concerning the development of a metric that is able to deal with trust and distrust. The question is on how to combine successive distrust values on a path from a source node to a target node: should two distrust statements cancel or intensify each other? Recommendation Trust and Direct TrustReaders and authors are integrated in a single network because each scientist can be reviewer for some articles and author of some other articles. This results in two different kinds of edges [Beth et al., 1994]. Direct trust in an author's capabilities, i.e., to write good and scientifically correct papers, can be distinguished from recommendation trust, i.e., trust in the quality of someone's trust statements and reviews. Explicit trust or distrust in an author can replace an individual review on each of the author's papers. Distrust statements concerning someone's recommendations - reviews or trust statements - could exclude this person's recommendations from the overall recommendation. Trust Related to TopicsTrust statements should always be related to a specific research topic because users only rarely are experts in all available topics. Research topics should be organized in some way that permits inferring that someone who is trusted in some topic A is also trusted in some topic B in the case that topics A and B are related in some way. Topics can be organized for instance in a hierarchical structure (e.g., [Chen and Singh, 2001]). It can be inferred that someone who is expert in a subtopic has certain knowledge about the super-topic and to some limited extent about the siblings, too. Hierarchical classification schemes are used in the context of libraries to structure books and journals. In the computer sciences, hierarchical classifications exist like the computing classification system (CCS) from the ACM (Association for Computing Machinery)8. It provides a proper index of literature from the computer sciences according to their subject and hence facilitates retrieval. The CCS is even available as xml-file and could therefore easily be integrated in a trust management system. Furthermore, considerable numbers of scientific papers from the computer sciences are already classified according to the CCS because all authors publishing their papers with the ACM have to provide the categories of the paper and the general terms according to the classification. Instead of organizing research topics in a hierarchy, they could be modeled in a semantic network with weighted edges, i.e. a dependency graph, as, for example, proposed by [Kinateder and Rothermel, 2003]. In a dependency graph, the semantic closeness between two topics is annotated. Trust in one topic hence influences the trust in another topic according to the weight of the relationships between the first and the second topic in the dependency graph. It would be possible to map the CCS hierarchical classification including the "terms" to a dependency graph. Weights between edges must be set manually. Confidence in Trust StatementsConfidence values in trust statements permit handling trust statements in a more elaborated way. The confidence values could be objective or subjective. Objective ones are computed on the basis of the interaction history between users. The number of interactions and their recency are indicators for the reliability of the trust statement. Subjective confidence values are indicated by the user. They represent the user's individual opinion about the reliability of the assigned trust statements. It will be analyzed how the subjective confidence can be included in this approach and how it can be combined with the trust concepts. Introducing Trust ConceptsThe work described in this paper proposes using trust concepts instead of simple numerical values. Trust concepts offer a higher expressiveness in contrast to numerical values, which only permit indicating trust relationships on a continual scale but not expressing two different, not directly comparable trust concepts. Concepts expressing a scientist's trust in the expertise of a colleague could, for example, permit distinguishing the following criteria:
Neither example above of trust concepts are directly comparable. A lattice-based structure organizes the trust concepts in a hierarchical fashion that permits comparing the concepts in some way. Research IssuesBased on the described use case for supporting researchers' decisions on whether to read an article or to buy a pay-per-view article, a number of research issues have been identified. The approach is not restricted either to a mere analysis of the document network like it is done by search engines or to an isolated consideration of the trust network like commercial recommender systems such as Epinions, but integrates knowledge from various sources into a multi-layer network. The different aspects of a trust management system will be implemented in a prototype trust management system that realizes the use case. Users of the system will be the members of research groups with an interdisciplinary background. Trust and review data that is inserted by the users can be used to directly evaluate the approach. The quality of recommendations and the added value by the trust management system can be evaluated with the help of user feedback. As the presented dissertation project is just beginning, there remain several open research questions that are addressed in the ongoing work. Research on the theoretical foundations of the presented trust management is twofold. On the one hand, interdependencies between the layers will be analyzed. The trust network cannot be viewed as independent from the document network. An author who has written many visible papers could be perceived by a reader as more trustworthy than another author of less visible papers, even though the reader has been very satisfied with both authors. The trust network is coupled with an organization network, too. Inter-organizational trust is influenced by the trust between the members of the organization and vice versa. On the other hand, the modeling of the trust concepts is an important part. The modeling technique must be chosen. Ontologies seem to be a good approach. However, other modeling approaches will be evaluated. Having modeled trust statements as concepts, further research issues emerge, for instance on trust metrics. Confidence can no longer be easily obtained from complex trust concepts. A trust metric for trust propagation has to be developed that can deal with complex trust concepts, instead of using the current metrics that calculate trust scores based on numerical values. However, research is not restricted to the theoretical aspects, and novel ideas will be evaluated with the help of prototypical implementations. Another research issue is exploring further application scenarios for trust management. In the context of digital libraries, personalization of services offered by those digital libraries could be enhanced. Digital preservation could be another application domain: the selection of which documents to convert directly to a new format or to convert only on demand can be supported by a multi-layer network approach. BibliographyBeth et al., 1994 Börner et al.,
2004 Chen and Singh, 2001 Golbeck et al.,
2003 Guha, 2003 Guha et al., 2004 Kinateder and
Rothermel, 2003 Malsch and Schlieder,
2002 Montaner et al.,
2002 Page et al., 1998 Ziegler and Lausen,
2004 Appendix: Laboratory for Semantic Information TechnologyChristoph Schlieder Laboratory for Semantic Information
Technology, The University of Bamberg, founded in 1647 under the name of Academia Bambergensis, is a research-oriented academic institution with about 8,000 students. In 2002, the Research Group on Computing in the Cultural Sciences and its home, the Laboratory for Semantic Information Technology were established. Currently, the group consists of six researchers from computer science, headed by Professor Schlieder, who adapt methods from semantic information processing for building information systems for the cultural sciences. The group focuses on two application domains: digital libraries with a special emphasis on computer-mediated communication, and geoinformation systems including mobile applications. Researchers of the group are engaged in several projects on the national and European level. The group has developed technology supporting mobile documentation, for instance a digital archive for medieval cathedrals. New methods and concepts for archiving and documentation constitute the basis for the monitoring of environmentally related damage on historic buildings. Furthermore, a video archive that permits combining video sequences to complete movies according to the target group is developed. Currently, it is used to annotate and manage video sequences about restoration techniques demonstrated in the dominican church in Bamberg. Video sequences will be retrieved by a semantic search and combined with movies, for instance demonstrating to students in cultural heritage the application of the restoration technologies. The project TeDUB ("Technical Drawings Understanding for the Blind") is part of the Information Society Technologies (IST) program funded by the European Union. The objective of TeDUB is to make technical drawings in digital documents accessible to blind users. In the project, software was developed that interprets the diagrams and allows users to navigate through them. Research in computer-mediated communication is undertaken in the context of the project Communication Oriented Modeling (COM) funded by the German science foundation (Deutsche Forschungsgemeinschaft), which comprises studying and modeling of large scale communication processes. Communication processes are simulated and monitored over long time spans (see [Malsch and Schlieder, 2002]). For example, examinations into why some communication threads are very active despite of changing actors are being made. A central aspect is the analysis of social visibility, i.e., the question of why some messages or documents are highly referenced or often accessed. Claudia Hess works as a research assistant in the Research Group on Computing in the Cultural Sciences since 2004. Her dissertation project "Trust-management in Multi-Layer Networks" is in its first year and embedded in the group's research activities on digital libraries. A close cooperation takes place with the COM project. Modeling trust relationships between persons is of interest for the COM project as communication processes are always influenced by the people publishing documents and the relationships between them. Trust is one of the social relationships that heavily influence the behavior of persons, for instance for co-authorships. Claudia Hess' research therefore also supports the modeling of actors and of their behavior. The integration of document and trust networks is related to the COM project in the sense that search, selection and evaluation of documents or messages in large scale communication processes can be supported by the inclusion of trust information. Her experiences in semantic modeling (see [Hess and Schlieder, 2004], [Hess and de Vries, 2004]), above all ontological modeling, obtained during her diploma thesis and in the ongoing dissertation project, permit her to give input to the digital library projects such as the video archive. Bibliography for the AppendixMalsch and Schlieder,
2002 Hess and Schlieder,
2004 Hess and de Vries,
2004 Notes1 Epinions. <http://www.epinions.com>. 2 Ebay. <http://www.ebay.com>. 3 Deutsche Forschungsgemeinschaft 2004 <http://www.dfg.de/aktuelles_presse/reden_stellungnahmen/2004/download/ha_jhschoen_1004_en.pdf>. 4 Publications: Schön, J. H., Berg, S., Kloc, Ch. and Batlogg, B. (2000): Ambipolar Pentacene Field-Effect Transistors and Inverters, Science 287, 1022 and Schön, J. H. , Kloc, Ch., Laudise, R. A. and Batlogg, B. (1998): Electrical Properties of Single Crystals of Rigid Rodlike Conjugated Molecules, Physical Review B 58, 12952. 5 The NASA Astrophysics Data System System http://adsabs.harvard.edu>. Last accessed 27.05.05. 6 CiteSeer. <http://citeseer.ist.psu.edu>. 7 FilmTrust. <http://trust.mindswap.org/FilmTrust>. 8 ACM Computing Classification Ssytem: <http://www.acm.org/class>. © Copyright 2006 Claudia Hess Top | Contents |